Back to Public Engagement

Towards Always-On Wearable AI That Perceives, Understands, and Assists
📅 June 3, 2026 · 17:00–17:30 📍 Room 108 🎤 Antonino Furnari
This presentation outlines a framework for Collaborative AI, focusing on three pillars: sensing the world under physical constraints (Cognitive Economy), grounding perception into external structures (Knowledge Grounding), and providing empowering user feedback (Optimal Intervention).
⚡
Cognitive Economy
Sensing under energy & compute constraints
🔗
Knowledge Grounding
Grounding perception in external structures
🎯
Optimal Intervention
Empowering feedback at the right moment
Featured Research
Works presented during the talk. Click on a paper to explore the full research page.
🥽 ⚡ Cognitive Economy
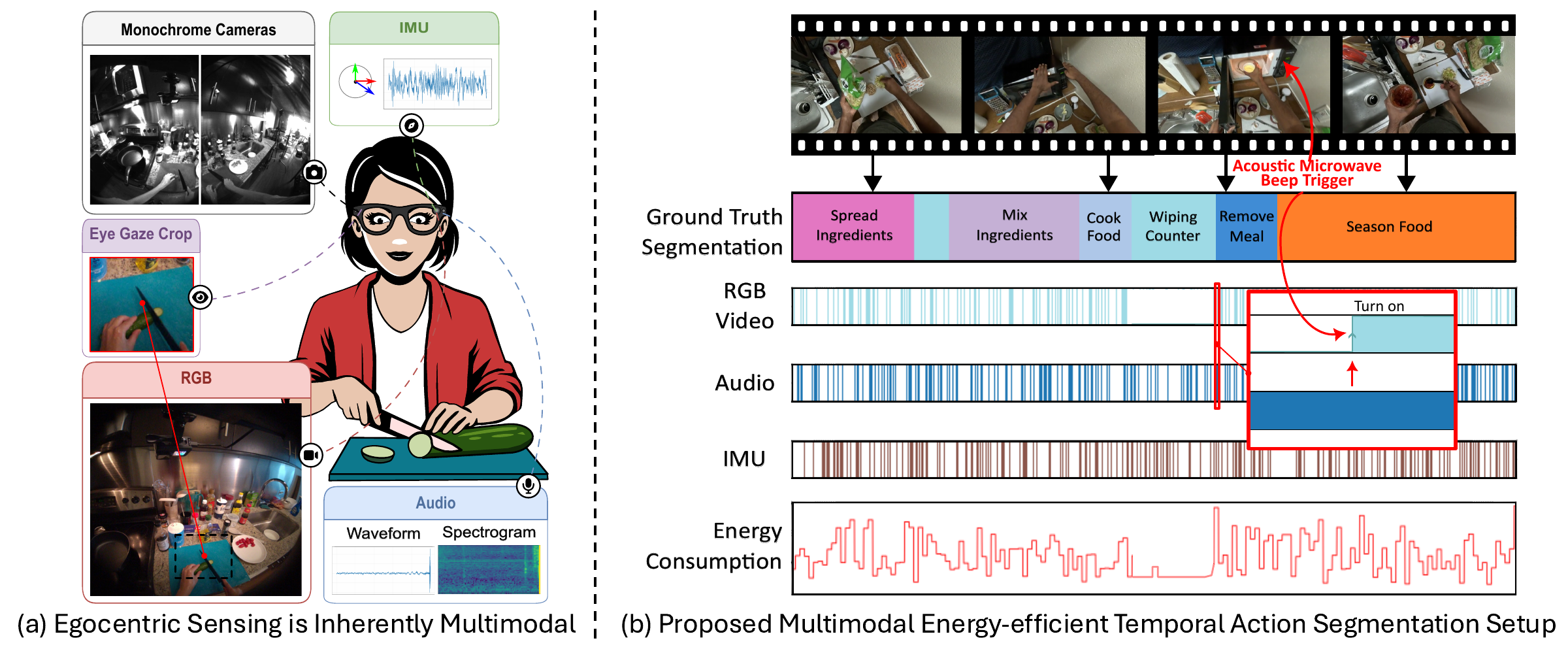
Ego-METAS Multimodal Energy-Efficient Temporal Action Segmentation
Focus: Multimodal efficient sensing and energy-aware policies for wearable devices.
Overview: This work introduces a benchmark addressing the "Infinite Scaling Assumption" by evaluating how egocentric online models perform under strict energy budgets (e.g., 20mW).
Key Finding: Exhaustive processing heavily drains batteries, whereas greedy and learned policies for framerate reduction provide a more sustainable approach to continuous sensing.
🧠 ⚡ Cognitive Economy
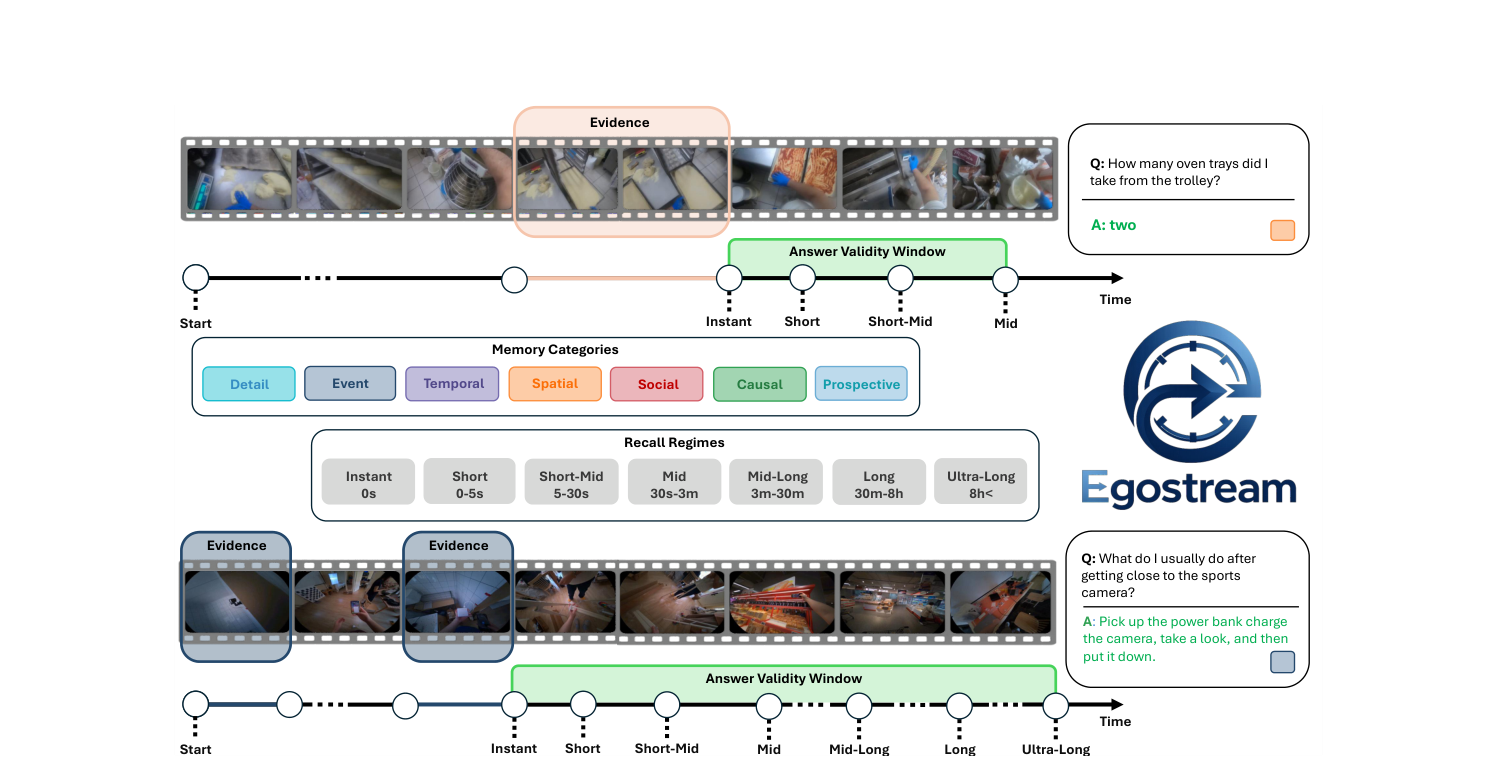
EgoStream Streaming Episodic Memory in Egocentric Vision
Focus: A diagnostic benchmark for assessing episodic memory in AI across various temporal recall regimes, from instant (0s) to ultra-long (>8h).
Overview: We explore memory management strategies like pruning, merging, and offloading within a fixed memory budget to maintain continuous video streams.
Key Finding: Pruning-based memory management generally outperforms merging and offloading, though offloading recovers performance in ultra-long recall scenarios.
📊 🔗 Knowledge Grounding
🏆 CVPR 2026 Highlight · Top 14%
✅ CVPR 2026 Efficient Badge
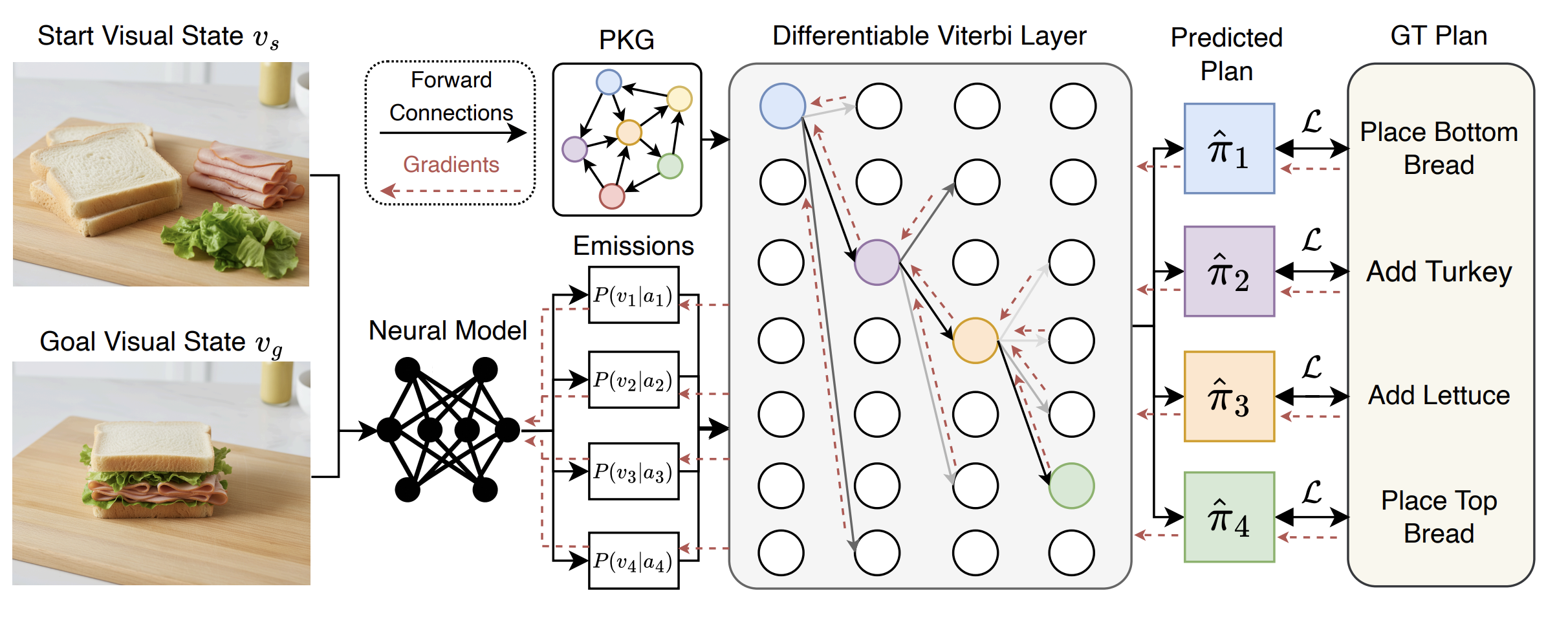
ViterbiPlanNet Injecting Procedural Knowledge for Video Planning
Focus: Using procedural graphs as cognitive support to inject knowledge into the learning process via a Differentiable Viterbi Layer.
Overview: This method addresses cognitive offloading by allowing base models to rely on structured graphs rather than memorizing full procedures.
Key Finding: Achieves state-of-the-art success rates with an order of magnitude fewer parameters (e.g., 5.58M) and demonstrates strong sample efficiency and cross-horizon generalization.
🛠️ 🔗 Knowledge Grounding
RECIPE Procedural Planning via Grounding in Instructional Video
Focus: A dual-input configuration utilizing specialized procedural models to plan tasks from visual and textual histories.
Overview: The framework explores grounding as verification, utilizing noisy video corpora to build resilience against weak supervision and procedural diversity.
Key Finding: Meaningfully improves macro accuracy over supervised fine-tuning, especially in zero-shot environments.