Research Lines
Our research focuses on visual intelligence for Human-AI collaboration. We study how AI systems can perceive, understand, and anticipate what people are doing from first-person and multi-view observations, with the goal of supporting human activity through memory, skill-aware analysis, and timely assistance.
We focus on the following themes:
Procedural Understanding
Featured Work Gallery
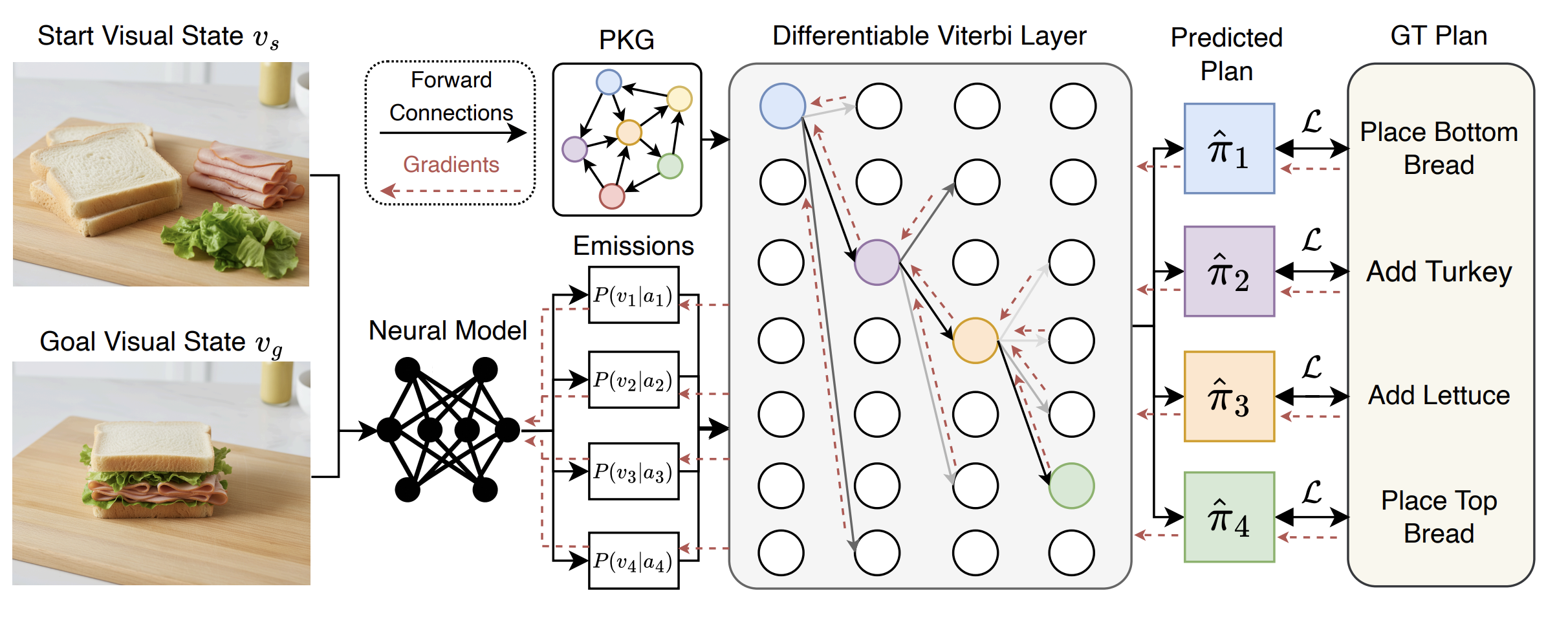
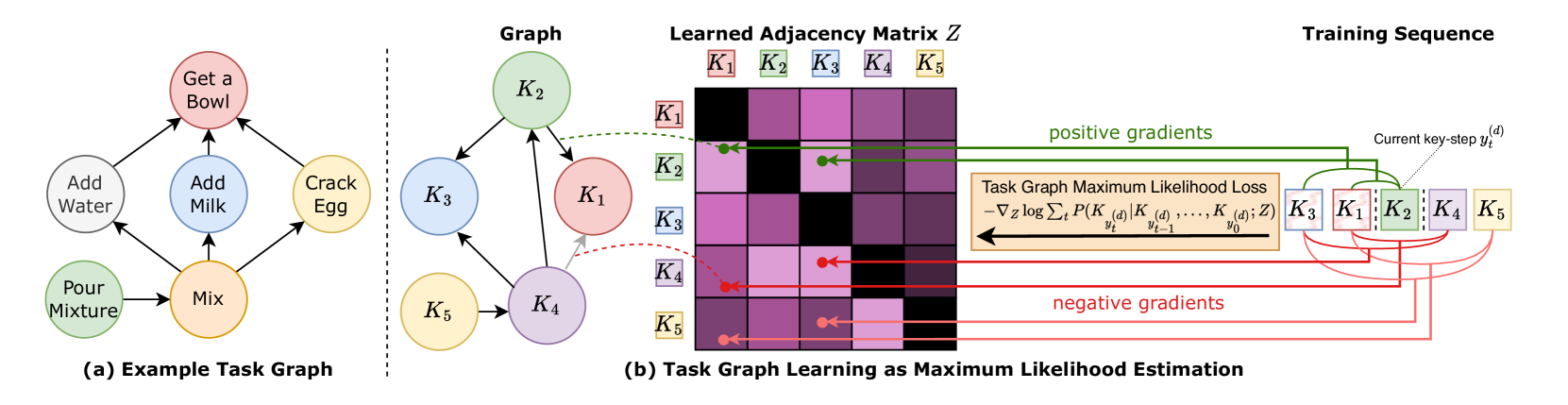
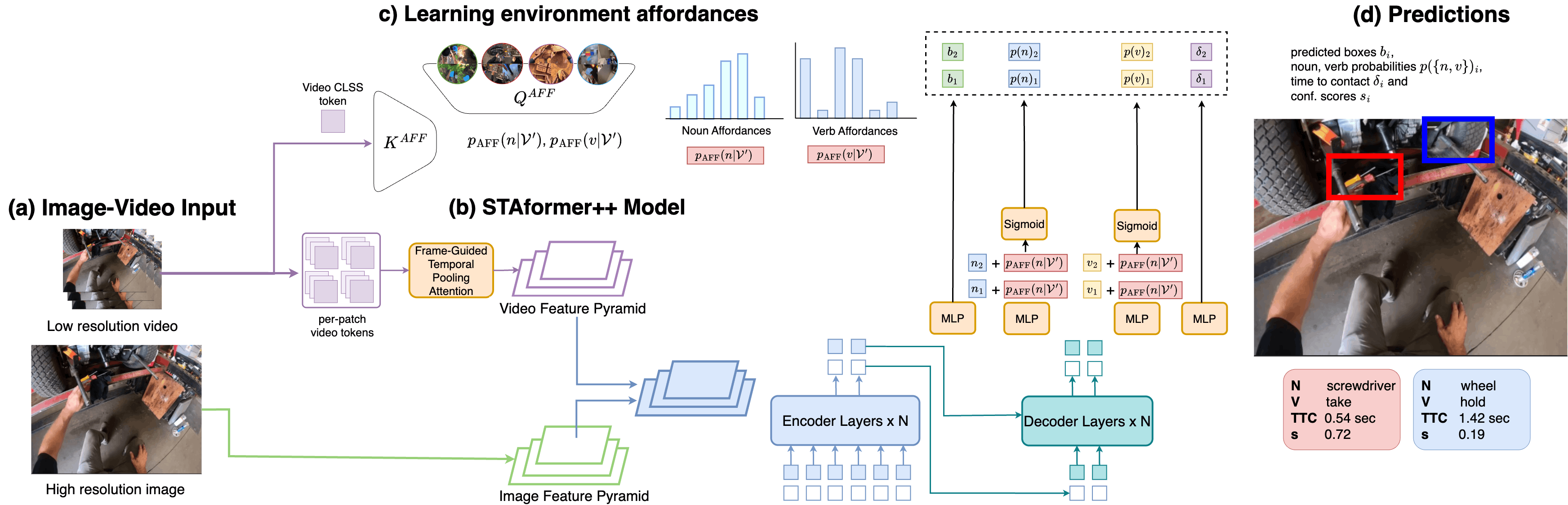
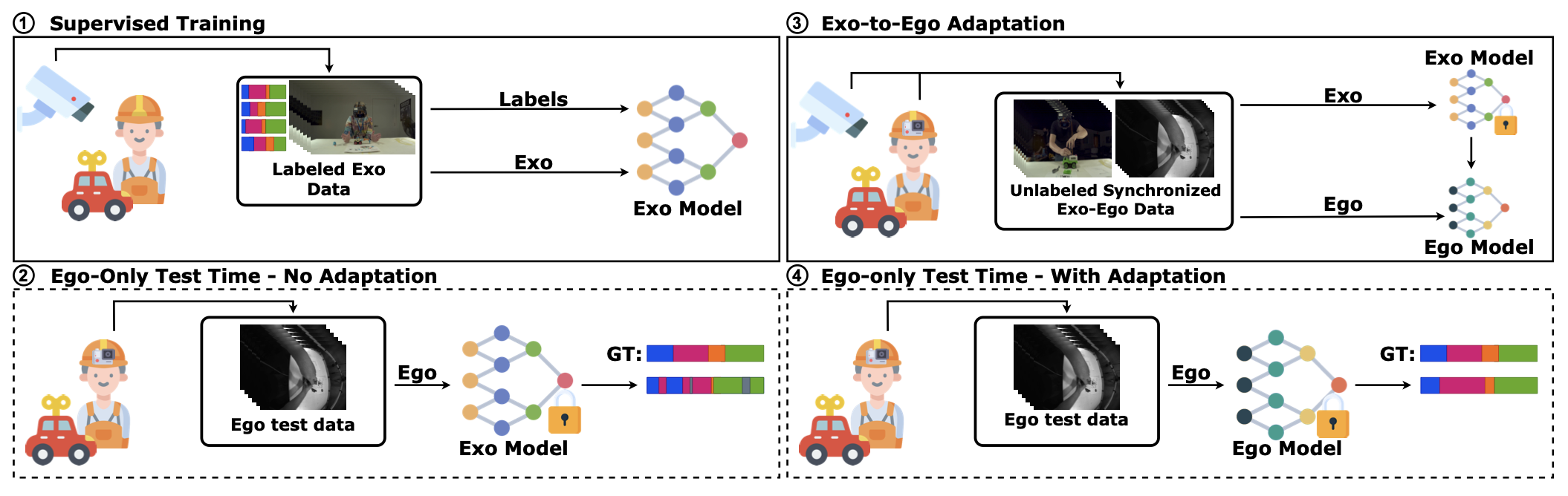
We study how complex activities unfold over time. Our work develops models for anticipating future actions, representing procedural structure, and reasoning over long-horizon tasks in egocentric and instructional video.
This line of research moves from early action anticipation toward structured procedural reasoning, including task graphs, action segmentation, and planning-aware representations that capture not only what happens next, but how actions are organized into coherent processes.
Linked Publications
Luigi Seminara , Davide Moltisanti , Antonino Furnari
Luigi Seminara , Giovanni Maria Farinella , Antonino Furnari
IEEE Transactions on Pattern Analysis and Machine Intelligence
Lorenzo Mur-Labadia , Ruben Martinez-Cantin , Jose J. Guerrero , Giovanni Maria Farinella , Antonino Furnari
Camillo Quattrocchi , Antonino Furnari , Daniele Di Mauro , Mario Valerio Giuffrida , Giovanni Maria Farinella
International Journal on Computer Vision (IJCV)
Skill, Errors, and Assistance
Featured Work Gallery
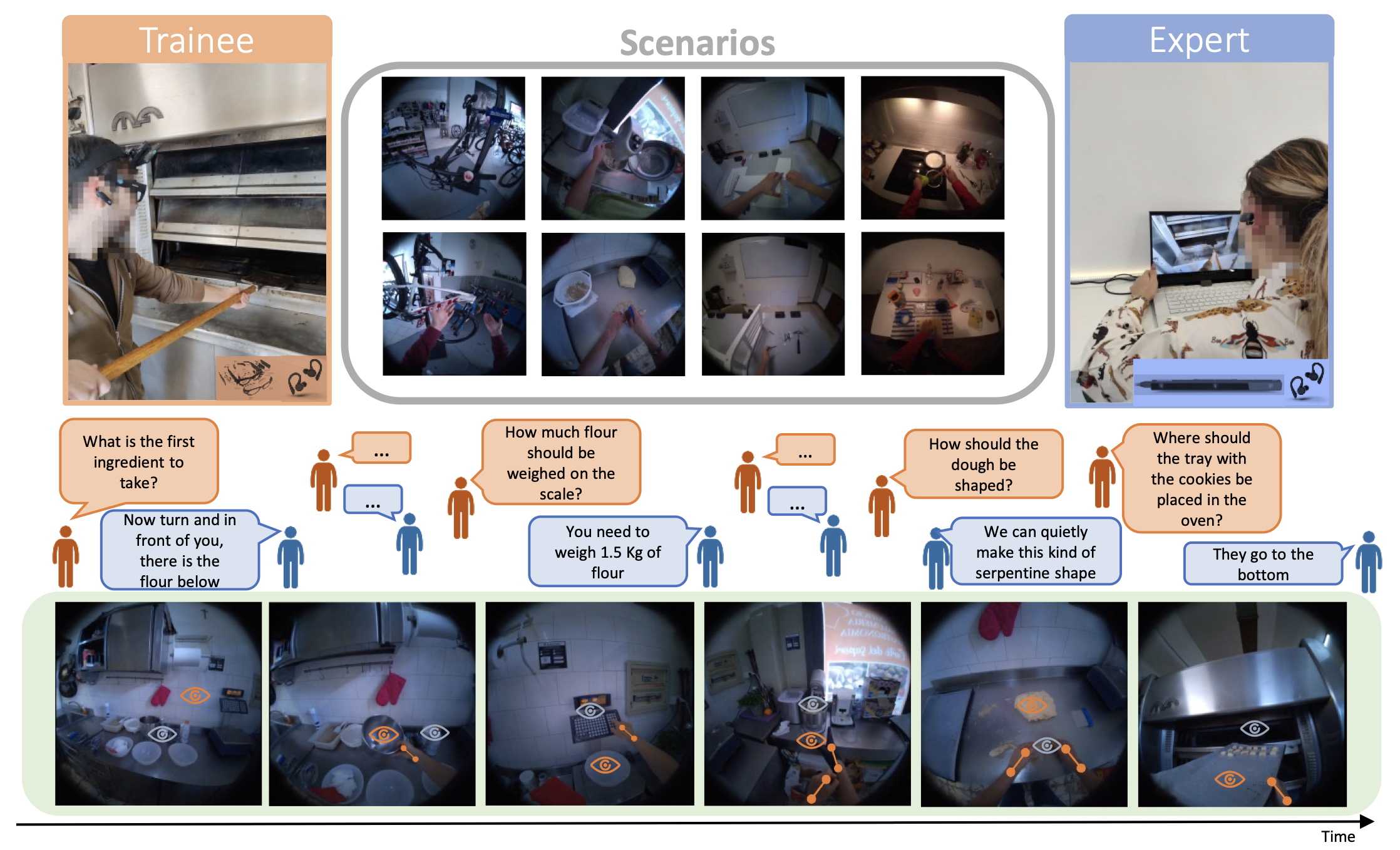

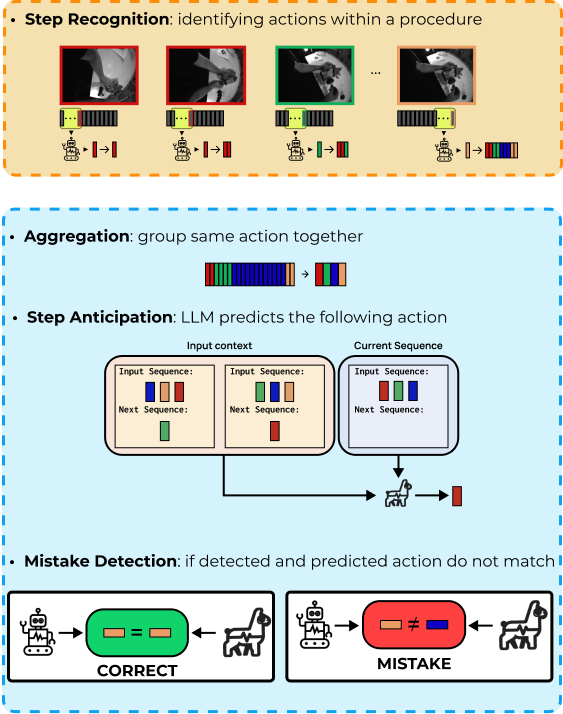
We develop methods that go beyond recognizing actions to evaluate how well they are performed. Our research in this area focuses on mistake detection, skill assessment, and assistive feedback for procedural activities, especially in egocentric settings where understanding the user’s intent and execution is crucial.
The long-term goal is to enable AI systems that can support people during real tasks by identifying deviations, anticipating difficulties, and providing timely, actionable guidance aligned with human autonomy.
Linked Publications
Francesco Ragusa , Michele Mazzamuto , Rosario Forte , Irene D'Ambra , James Fort , Jakob Engel , Antonino Furnari , Giovanni Maria Farinella
Luigi Seminara , Antonino Furnari , Lorenzo Torresani
Alessandro Flaborea , Guido D'Amely , Leonardo Plini , Luca Scofano , Edoardo De Matteis , Antonino Furnari , Giovanni Maria Farinella , Fabio Galasso
Memory and Streaming Intelligence
Featured Work Gallery
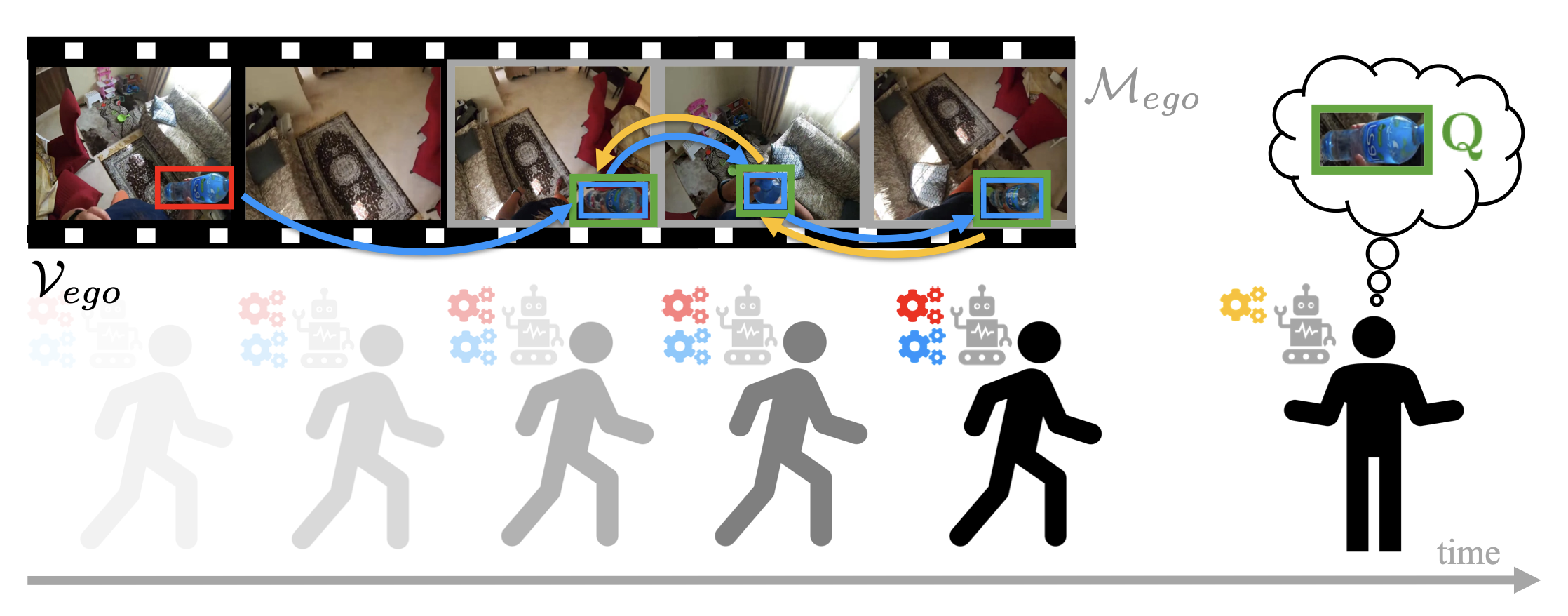
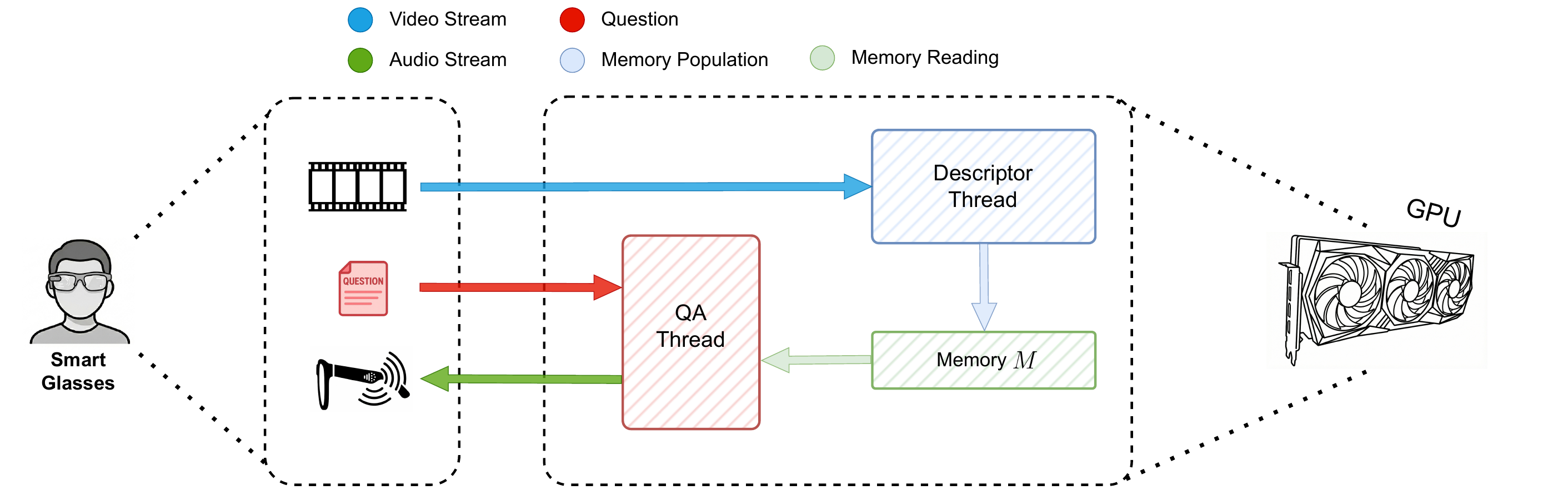
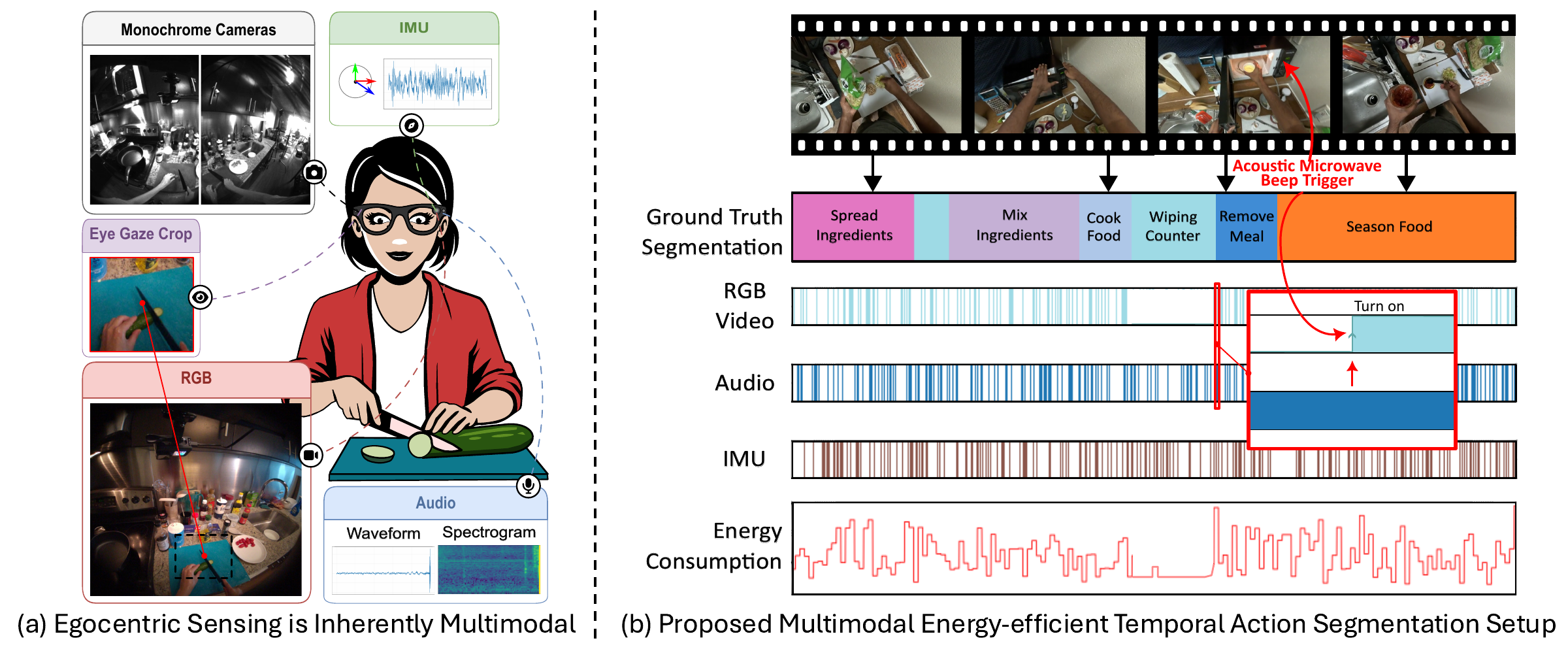
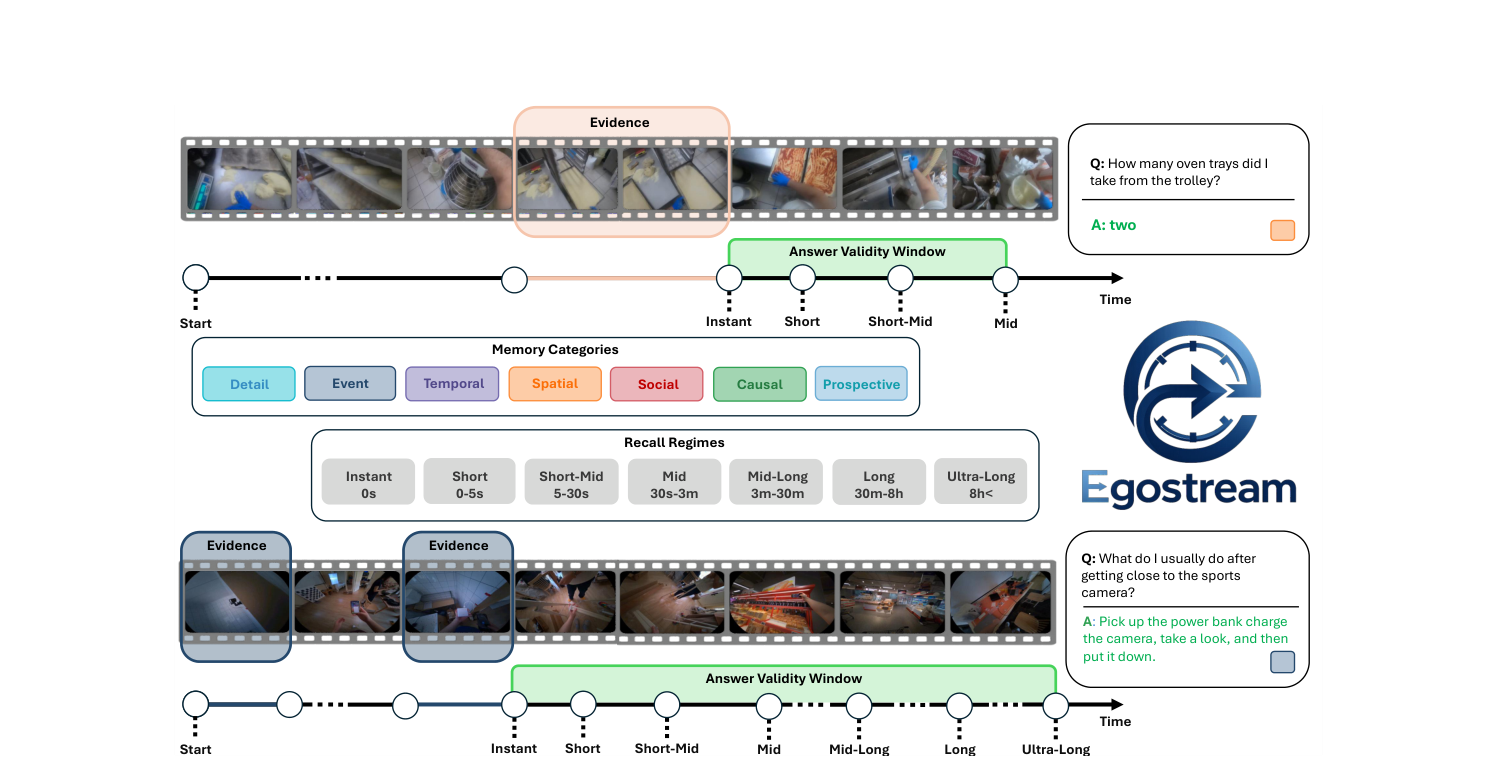
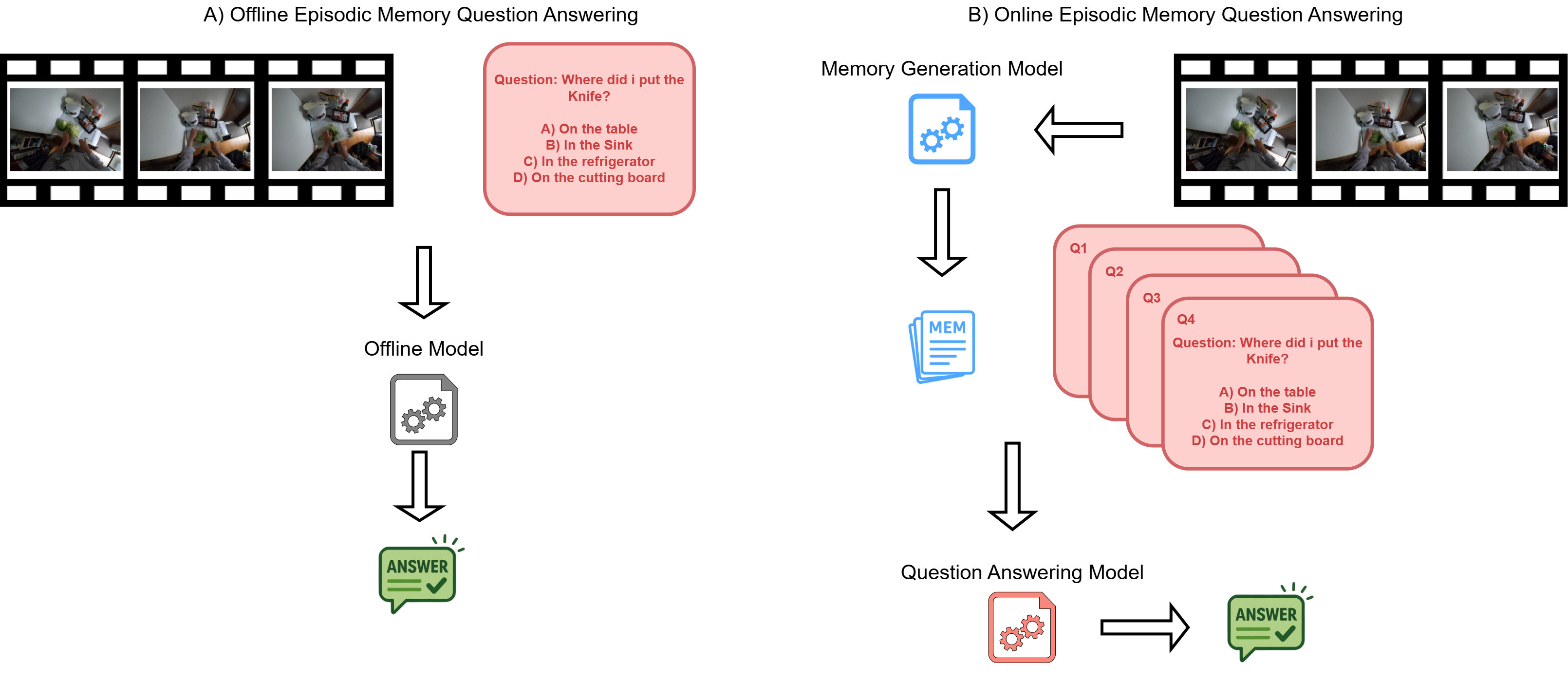
We investigate how AI systems can observe continuously, remember relevant past events, and reason over long streams of egocentric experience. This includes streaming perception, episodic memory, and multimodal question answering over events that unfold over time.
Our aim is to build systems that do not simply process isolated frames or clips, but maintain a compact and useful representation of ongoing experience, enabling context-aware reasoning and support in always-on wearable scenarios.
Linked Publications
Zaira Manigrasso , Matteo Dunnhofer , Antonino Furnari , Moritz Nottebaum , Antonio Finocchiaro , Davide Marana , Rosario Forte , Giovanni Maria Farinella , Christian Micheloni
IEEE Winter Conference on Application of Computer Vision (WACV)
Maria Santos-Villafranca , Jesus Bermudez-Cameo , Alejandro Perez-Yus , Giovanni Maria Farinella , Antonino Furnari
Raffaele Calì , Giuseppe Lando , Rosario Forte , Antonino Furnari
International Conference on Content-Based Multimedia Indexing (CBMI)
Giuseppe Lando , Rosario Forte , Giovanni Maria Farinella , Antonino Furnari
Datasets and Benchmarks
Featured Work Gallery

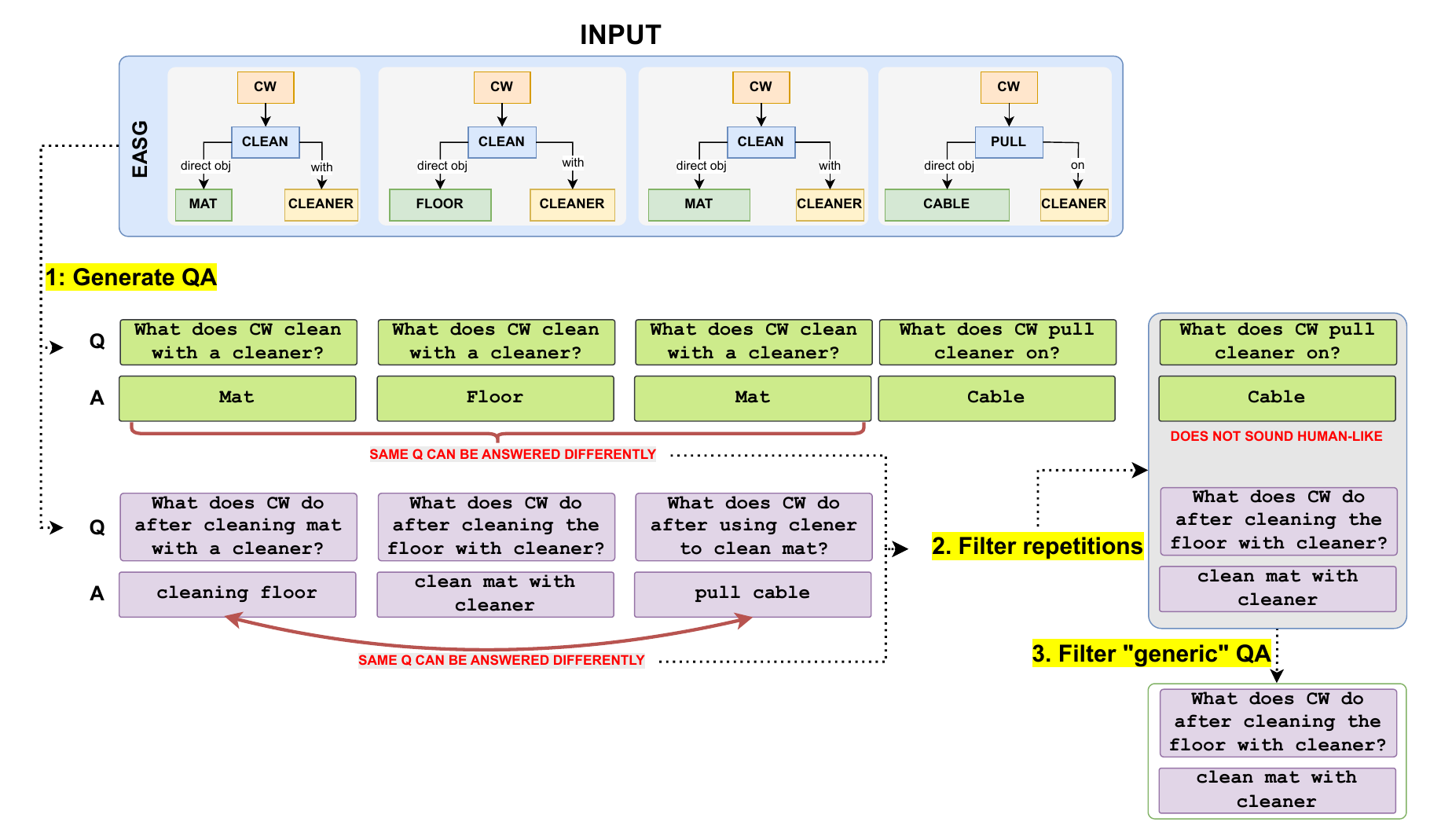
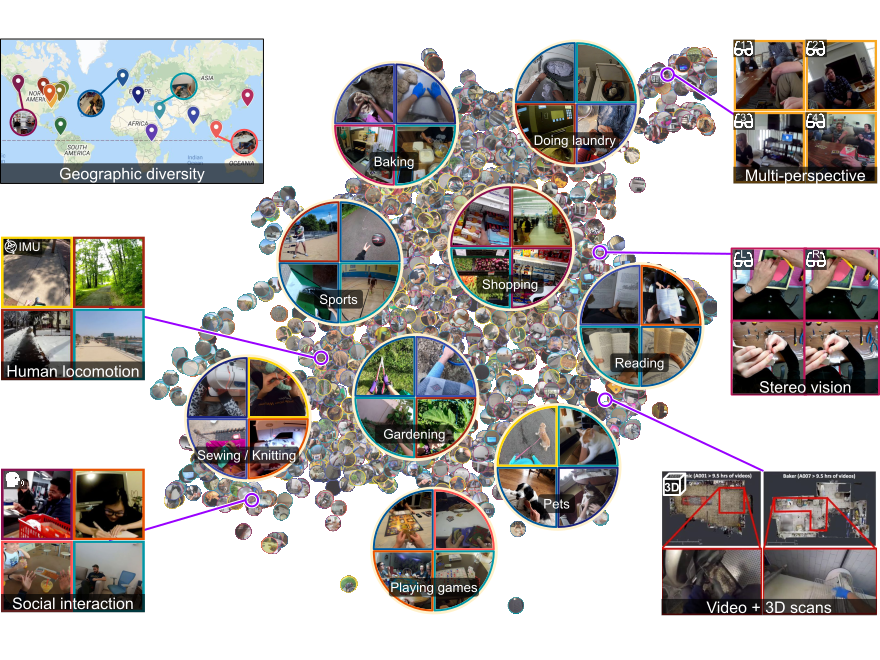
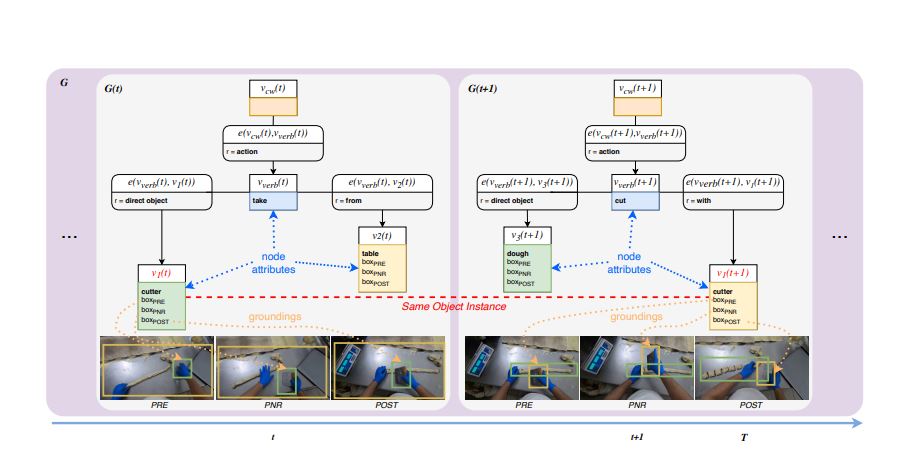
We contribute datasets, benchmarks, and evaluation protocols that help shape research in egocentric and procedural video understanding. These resources provide the community with challenging real-world scenarios for studying action recognition, anticipation, skill understanding, memory, and assistance.
By building shared benchmarks, we aim to support reproducible progress and enable new research directions at the intersection of first-person vision, multimodal learning, and human-centred AI.
Linked Publications
Francesco Ragusa , Michele Mazzamuto , Rosario Forte , Irene D'Ambra , James Fort , Jakob Engel , Antonino Furnari , Giovanni Maria Farinella
Maria Santos-Villafranca , Jesus Bermudez-Cameo , Alejandro Perez-Yus , Giovanni Maria Farinella , Antonino Furnari
Kristen Grauman , Andrew Westbury , Lorenzo Torresani , Kris Kitani , Jitendra Malik , Triantafyllos Afouras , Kumar Ashutosh , Vijay Baiyya , Siddhant Bansal , Bikram Boote , Eugene Byrne , Zach Chavis , Joya Chen , Feng Cheng , Fu-Jen Chu , Sean Crane , Avijit Dasgupta , Jing Dong , Maria Escobar , Cristhian Forigua , Abrham Gebreselasie , Sanjay Haresh , Jing Huang , Md Mohaiminul Islam , Suyog Jain , Rawal Khirodkar , Devansh Kukreja , Kevin J. Liang , Jia-Wei Liu , Sagnik Majumder , Yongsen Mao , Miguel Martin , Effrosyni Mavroudi , Tushar Nagarajan , Francesco Ragusa , Santhosh Kumar Ramakrishnan , Luigi Seminara , Arjun Somayazulu , Yale Song , Shan Su , Zihui Xue , Edward Zhang , Jinxu Zhang , Angela Castillo , Changan Chen , Xinzhu Fu , Ryosuke Furuta , Cristina González , Prince Gupta , Jiabo Hu , Yifei Huang , Yiming Huang , Weslie Khoo , Anush Kumar , Robert Kuo , Sach Lakhavani , Miao Liu , Mi Luo , Zhengyi Luo , Brighid Meredith , Austin Miller , Oluwatumininu Oguntola , Xiaqing Pan , Penny Peng , Shraman Pramanick , Merey Ramazanova , Fiona Ryan , Wei Shan , Kiran Somasundaram , Chenan Song , Audrey Southerland , Masatoshi Tateno , Huiyu Wang , Yuchen Wang , Takuma Yagi , Mingfei Yan , Xitong Yang , Zecheng Yu , Shengxin Cindy Zha , Chen Zhao , Ziwei Zhao , Zhifan Zhu , Jeff Zhuo , Pablo Arbeláez , Gedas Bertasius , David Crandall , Dima Damen , Jakob Engel , Giovanni Maria Farinella , Antonino Furnari , Bernard Ghanem , Judy Hoffman , C. V. Jawahar , Richard Newcombe , Hyun Soo Park , James M. Rehg , Yoichi Sato , Manolis Savva , Jianbo Shi , Mike Zheng Shou , Michael Wray
Ivan Rodin , Tz-Ying Wu , Kyle Min , Sharath Nittur Sridhar , Antonino Furnari , Subarna Tripathi , Giovanni Maria Farinella
Kristen Grauman , Andrew Westbury , Eugene Byrne , Vincent Cartillier , Zachary Chavis , Antonino Furnari , Rohit Girdhar , Jackson Hamburger , Hao Jiang , Devansh Kukreja , Miao Liu , Xingyu Liu , Miguel Martin , Tushar Nagarajan , Ilija Radosavovic , Santhosh Kumar Ramakrishnan , Fiona Ryan , Jayant Sharma , Michael Wray , Mengmeng Xu , Eric Zhongcong Xu , Chen Zhao , Siddhant Bansal , Dhruv Batra , Sean Crane , Tien Do , Morrie Doulaty , Akshay Erapalli , Christoph Feichtenhofer , Adriano Fragomeni , Qichen Fu , Abrham Gebreselasie , Cristina Gonzalez , James Hillis , Xuhua Huang , Yifei Huang , Wenqi Jia , Weslie Khoo , Jachym Kolar , Satwik Kottur , Anurag Kumar , Federico Landini , Chao Li , Yanghao Li , Zhenqiang Li , Karttikeya Mangalam , Raghava Modhugu , Jonathan Munro , Tullie Murrell , Takumi Nishiyasu , Will Price , Paola Ruiz Puentes , Merey Ramazanova , Leda Sari , Kiran Somasundaram , Audrey Southerland , Yusuke Sugano , Ruijie Tao , Minh Vo , Yuchen Wang , Xindi Wu , Takuma Yagi , Ziwei Zhao , Yunyi Zhu , Pablo Arbelaez , David Crandall , Dima Damen , Giovanni Maria Farinella , Christian Fuegen , Bernard Ghanem , Vamsi Krishna Ithapu , C.V. Jawahar , Hanbyul Joo , Kris Kitani , Haizhou Li , Richard Newcombe , Aude Oliva , Hyun Soo Park , James M. Rehg , Yoichi Sato , Jianbo Shi , Mike Zheng Shou , Antonio Torralba , Lorenzo Torresani , Mingfei Yan , Jitendra Malik
IEEE Transactions on Pattern Analysis and Machine Intelligence
Ivan Rodin , Antonino Furnari , Kyle Min , Subarna Tripathi , Giovanni Maria Farinella
Conference on Computer Vision and Pattern Recognition (CVPR)
Looking for the full publications list?
Explore our complete catalog of journal articles, conference papers, patents, and datasets.