
About
Publications
Luigi Seminara , Davide Moltisanti , Antonino Furnari
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Luigi Seminara , Giovanni Maria Farinella , Antonino Furnari
IEEE Transactions on Pattern Analysis and Machine Intelligence
Leonardo Plini , Luca Scofano , Edoardo De Matteis , Guido Maria D’Amely di Melendugno , Alessandro Flaborea , Andrea Sanchietti , Giovanni Maria Farinella , Fabio Galasso , Antonino Furnari
Computer Vision and Image Understanding
Lorenzo Mur-Labadia , Ruben Martinez-Cantin , Jose J. Guerrero , Giovanni Maria Farinella , Antonino Furnari
IEEE Transactions on Pattern Analysis and Machine Intelligence
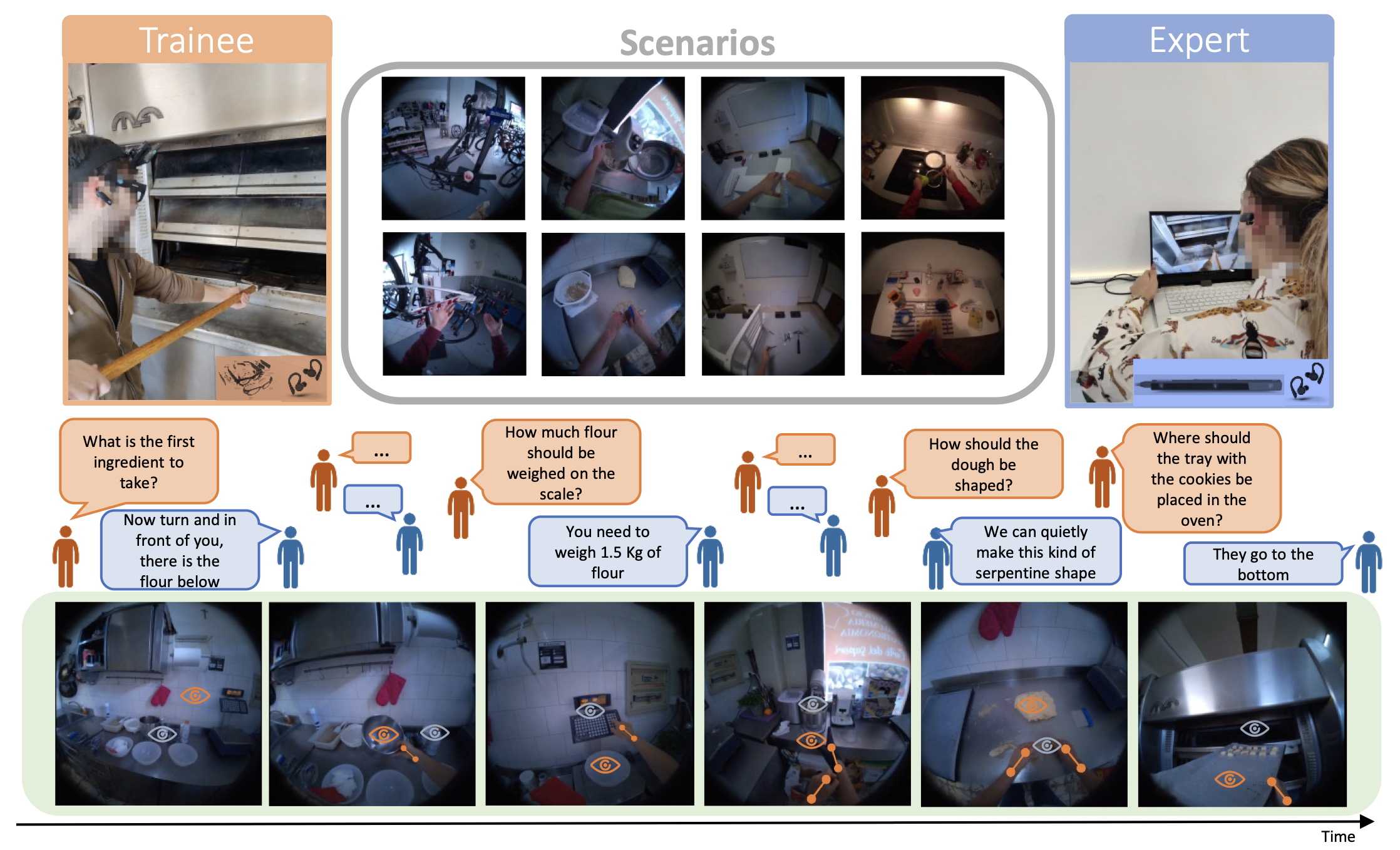
Francesco Ragusa , Michele Mazzamuto , Rosario Forte , Irene D'Ambra , James Fort , Jakob Engel , Antonino Furnari , Giovanni Maria Farinella
IEEE Winter Conference on Application of Computer Vision (WACV)
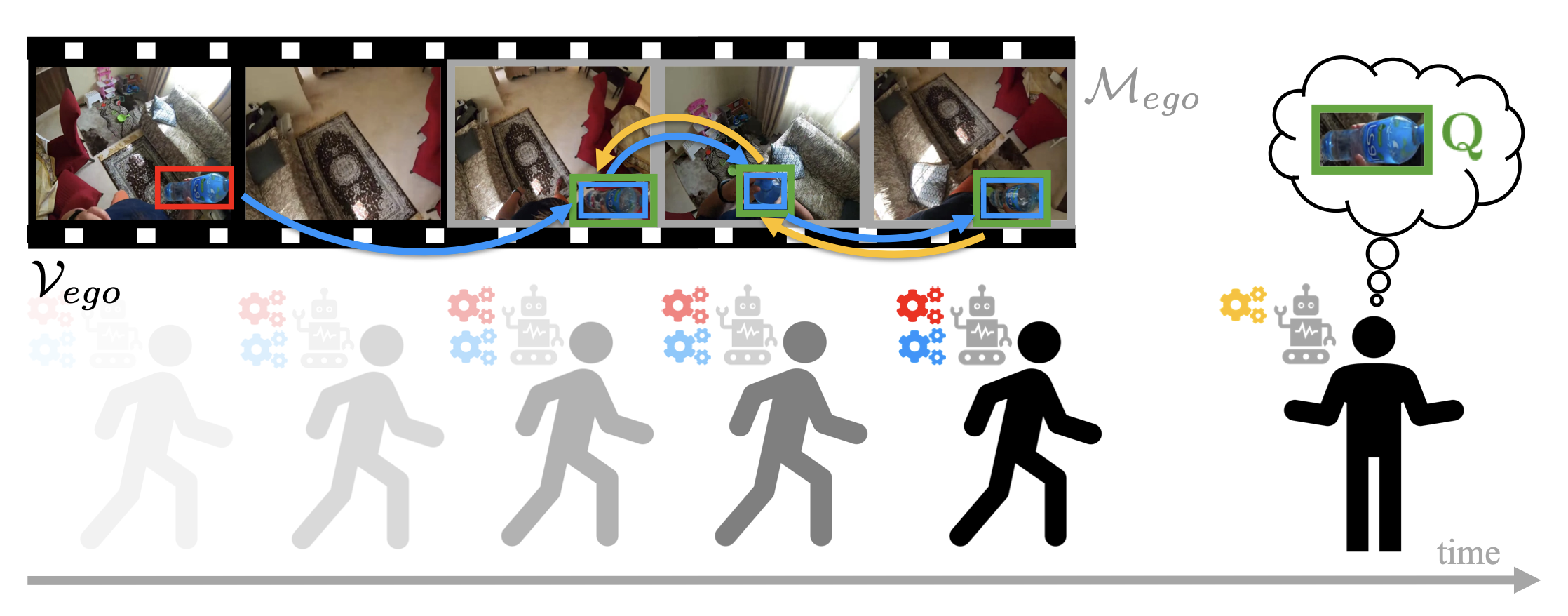
Zaira Manigrasso , Matteo Dunnhofer , Antonino Furnari , Moritz Nottebaum , Antonio Finocchiaro , Davide Marana , Rosario Forte , Giovanni Maria Farinella , Christian Micheloni
IEEE Winter Conference on Application of Computer Vision (WACV)
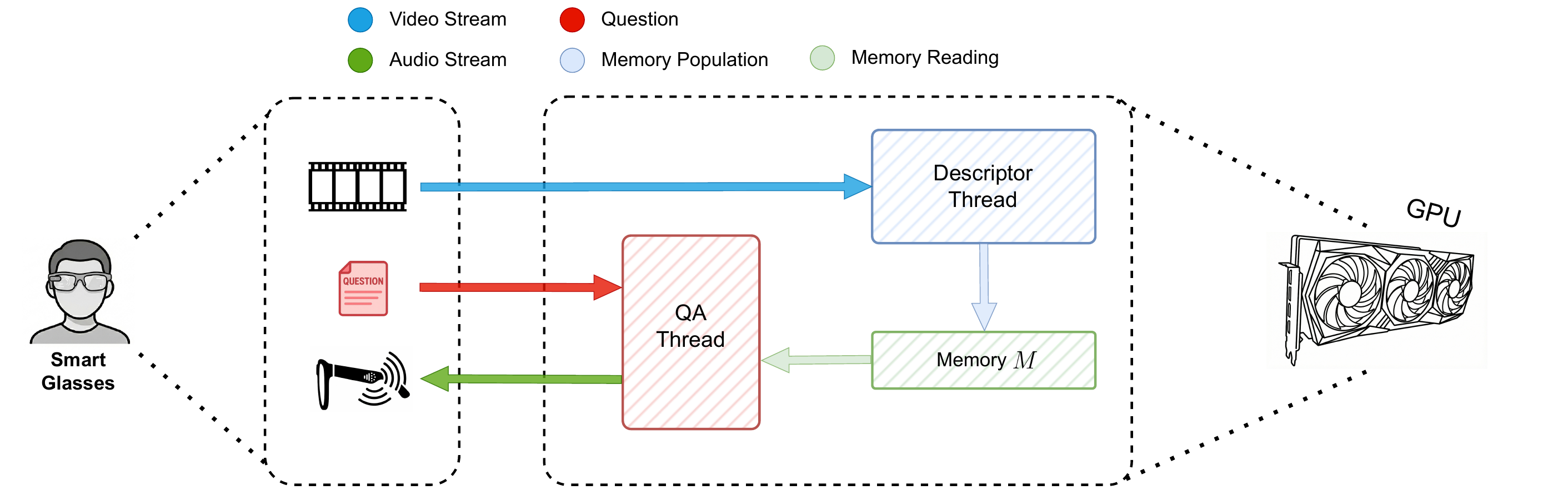
Giuseppe Lando , Rosario Forte , Antonino Furnari
International Conference on Computer Vision Theory and Applications (VISAPP)
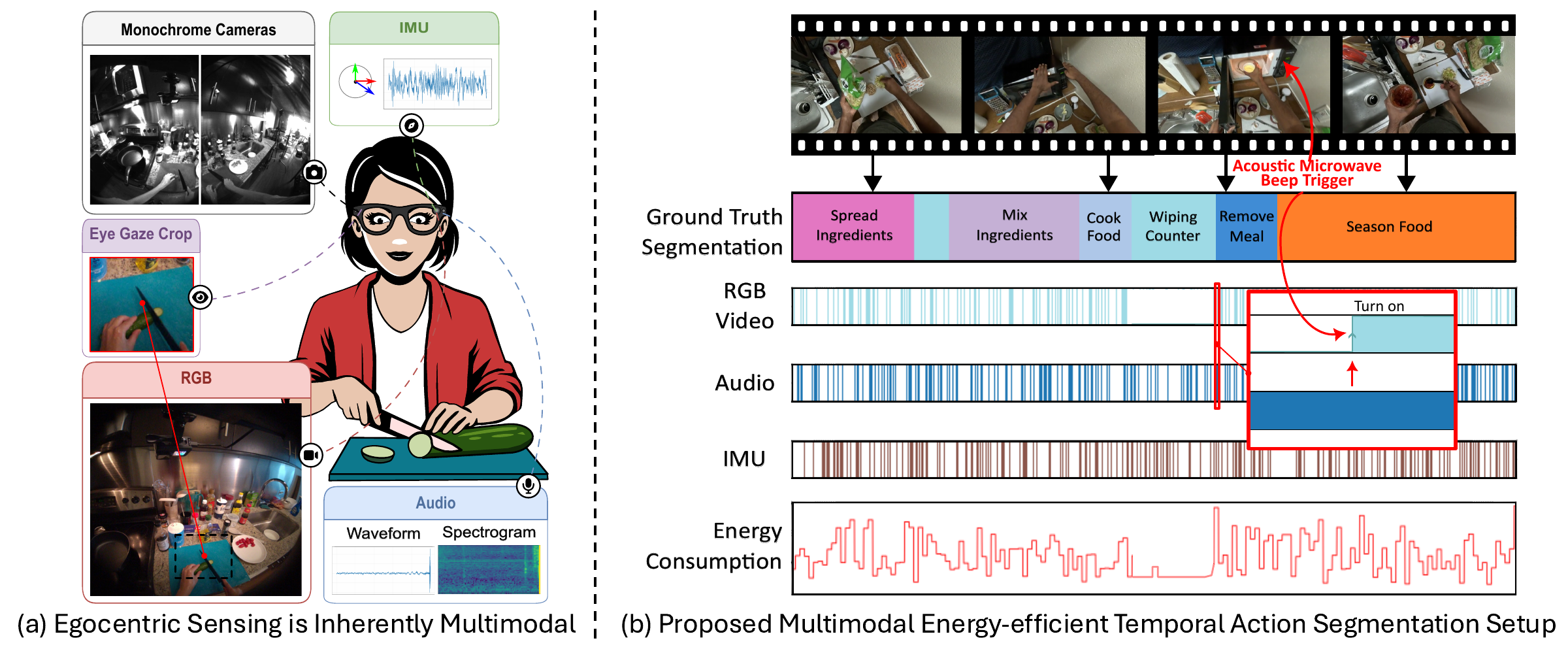
Maria Santos-Villafranca , Jesus Bermudez-Cameo , Alejandro Perez-Yus , Giovanni Maria Farinella , Antonino Furnari
arXiv preprint arXiv:2606.02246
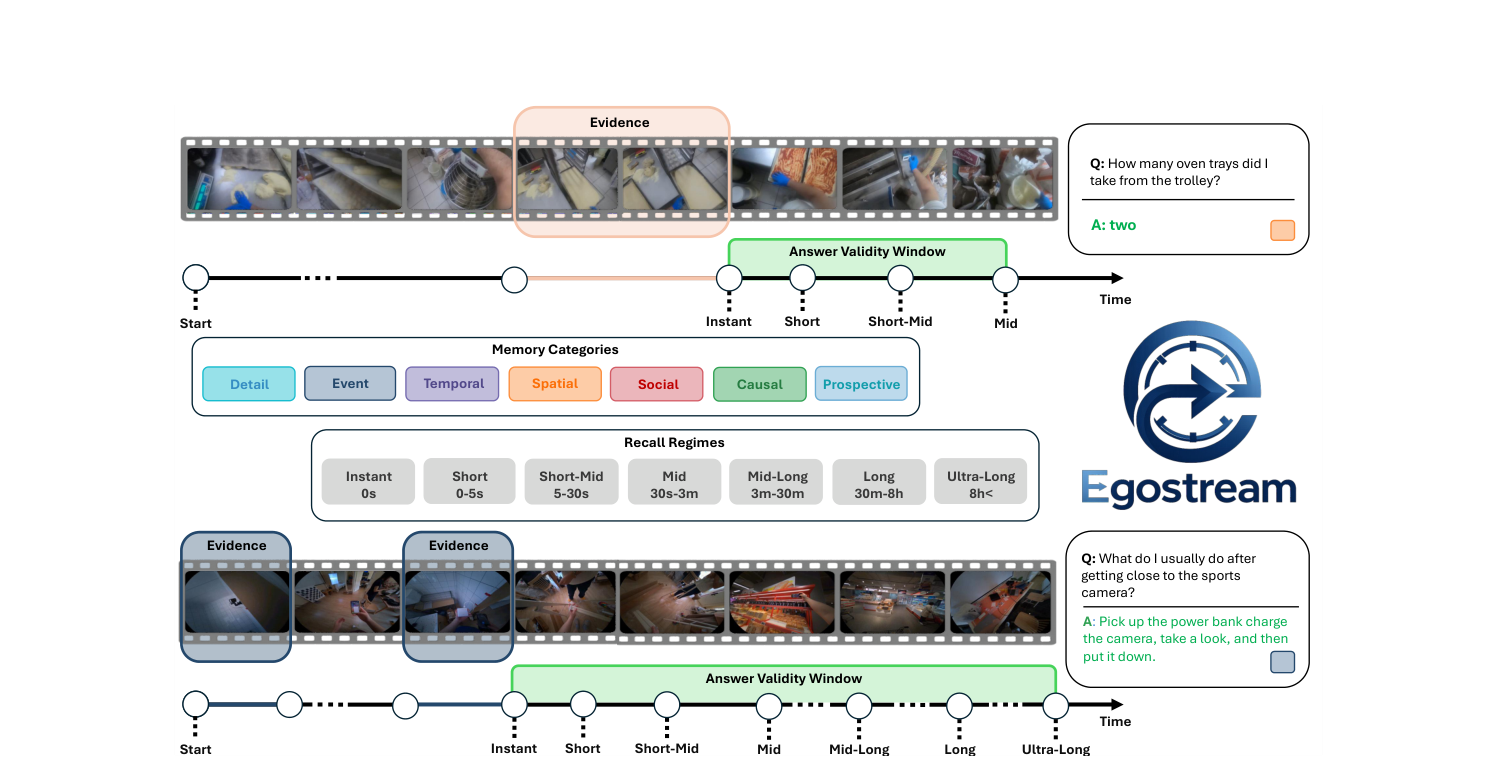
Rosario Forte , Giuseppe Lando , Antonino Furnari
arXiv preprint arXiv:2605.31557

Luigi Seminara , Antonino Furnari , Lorenzo Torresani
arXiv preprint arXiv:2605.19976
Raffaele Calì , Giuseppe Lando , Rosario Forte , Antonino Furnari
International Conference on Content-Based Multimedia Indexing (CBMI)
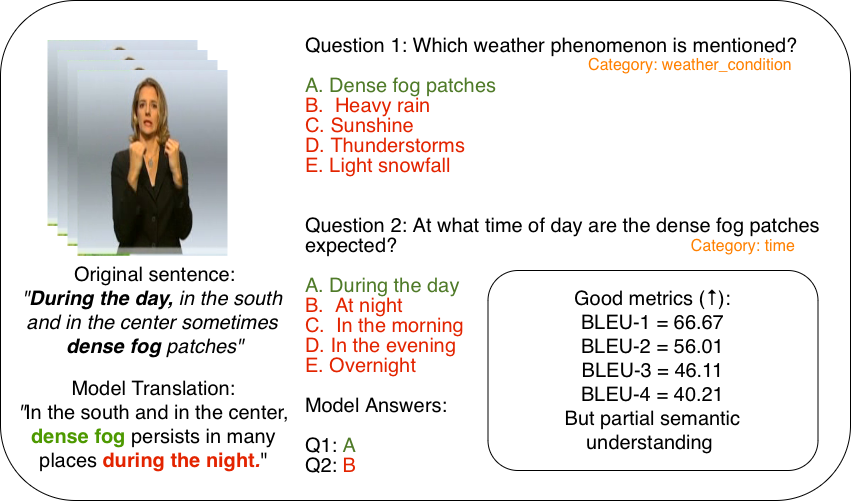
Zeno Testa , Antonino Furnari , Lorenzo Baraldi , Natalia Díaz-Rodríguez
arXiv preprint arXiv:2606.03788

Kristen Grauman , Andrew Westbury , Lorenzo Torresani , Kris Kitani , Jitendra Malik , Triantafyllos Afouras , Kumar Ashutosh , Vijay Baiyya , Siddhant Bansal , Bikram Boote , Eugene Byrne , Zach Chavis , Joya Chen , Feng Cheng , Fu-Jen Chu , Sean Crane , Avijit Dasgupta , Jing Dong , Maria Escobar , Cristhian Forigua , Abrham Gebreselasie , Sanjay Haresh , Jing Huang , Md Mohaiminul Islam , Suyog Jain , Rawal Khirodkar , Devansh Kukreja , Kevin J. Liang , Jia-Wei Liu , Sagnik Majumder , Yongsen Mao , Miguel Martin , Effrosyni Mavroudi , Tushar Nagarajan , Francesco Ragusa , Santhosh Kumar Ramakrishnan , Luigi Seminara , Arjun Somayazulu , Yale Song , Shan Su , Zihui Xue , Edward Zhang , Jinxu Zhang , Angela Castillo , Changan Chen , Xinzhu Fu , Ryosuke Furuta , Cristina González , Prince Gupta , Jiabo Hu , Yifei Huang , Yiming Huang , Weslie Khoo , Anush Kumar , Robert Kuo , Sach Lakhavani , Miao Liu , Mi Luo , Zhengyi Luo , Brighid Meredith , Austin Miller , Oluwatumininu Oguntola , Xiaqing Pan , Penny Peng , Shraman Pramanick , Merey Ramazanova , Fiona Ryan , Wei Shan , Kiran Somasundaram , Chenan Song , Audrey Southerland , Masatoshi Tateno , Huiyu Wang , Yuchen Wang , Takuma Yagi , Mingfei Yan , Xitong Yang , Zecheng Yu , Shengxin Cindy Zha , Chen Zhao , Ziwei Zhao , Zhifan Zhu , Jeff Zhuo , Pablo Arbeláez , Gedas Bertasius , David Crandall , Dima Damen , Jakob Engel , Giovanni Maria Farinella , Antonino Furnari , Bernard Ghanem , Judy Hoffman , C. V. Jawahar , Richard Newcombe , Hyun Soo Park , James M. Rehg , Yoichi Sato , Manolis Savva , Jianbo Shi , Mike Zheng Shou , Michael Wray
International Journal of Computer Vision
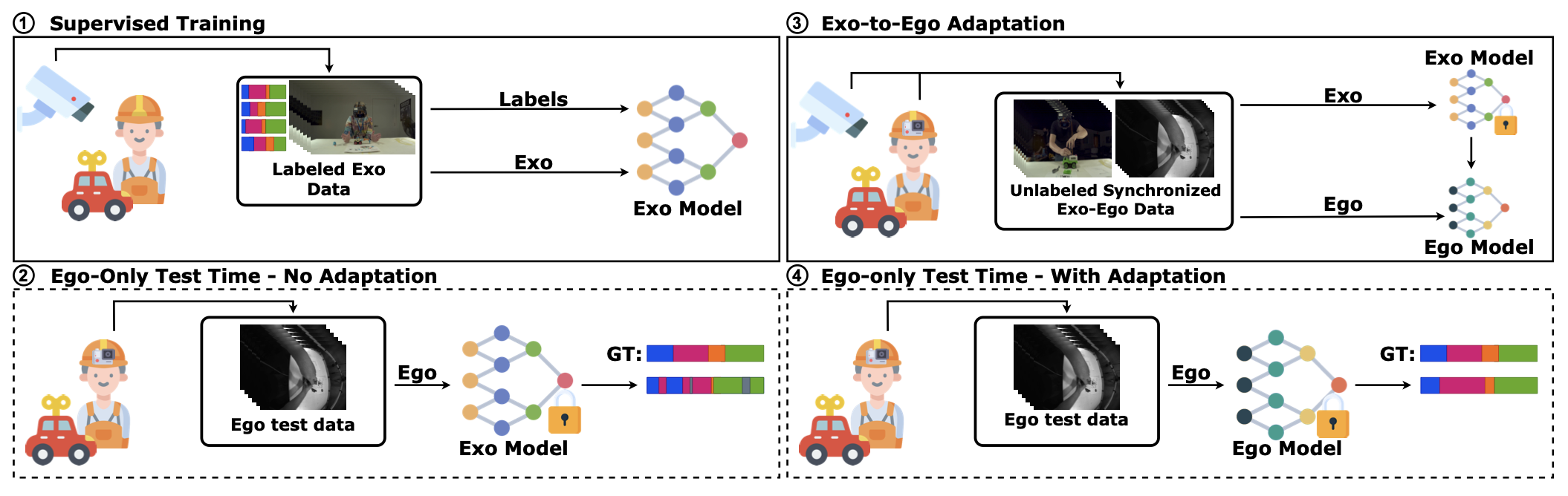
Camillo Quattrocchi , Antonino Furnari , Daniele Di Mauro , Mario Valerio Giuffrida , Giovanni Maria Farinella
International Journal on Computer Vision (IJCV)
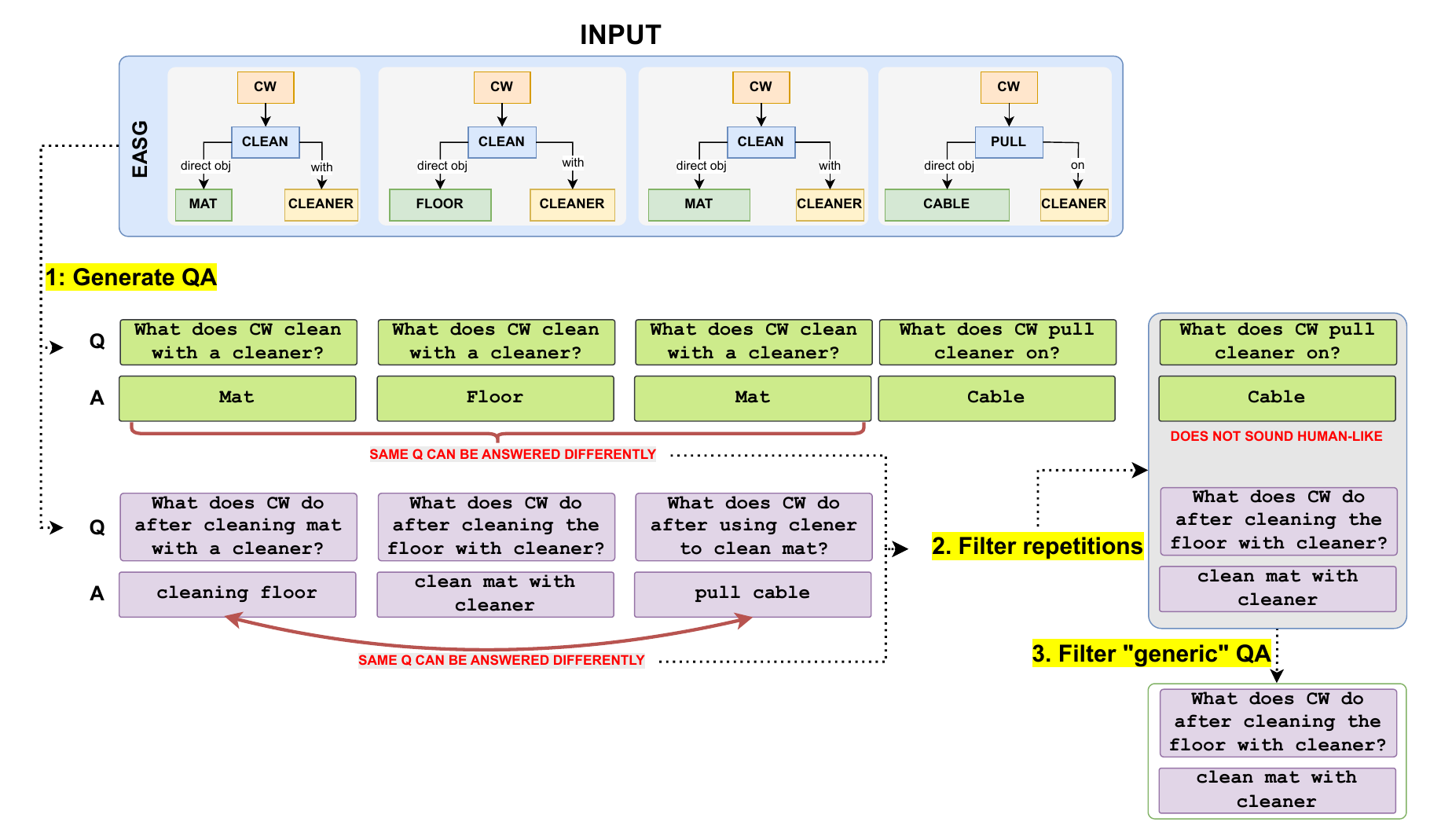
Ivan Rodin , Tz-Ying Wu , Kyle Min , Sharath Nittur Sridhar , Antonino Furnari , Subarna Tripathi , Giovanni Maria Farinella
IEEE/CVF International Conference on Computer Vision Workshops (ICCVW)
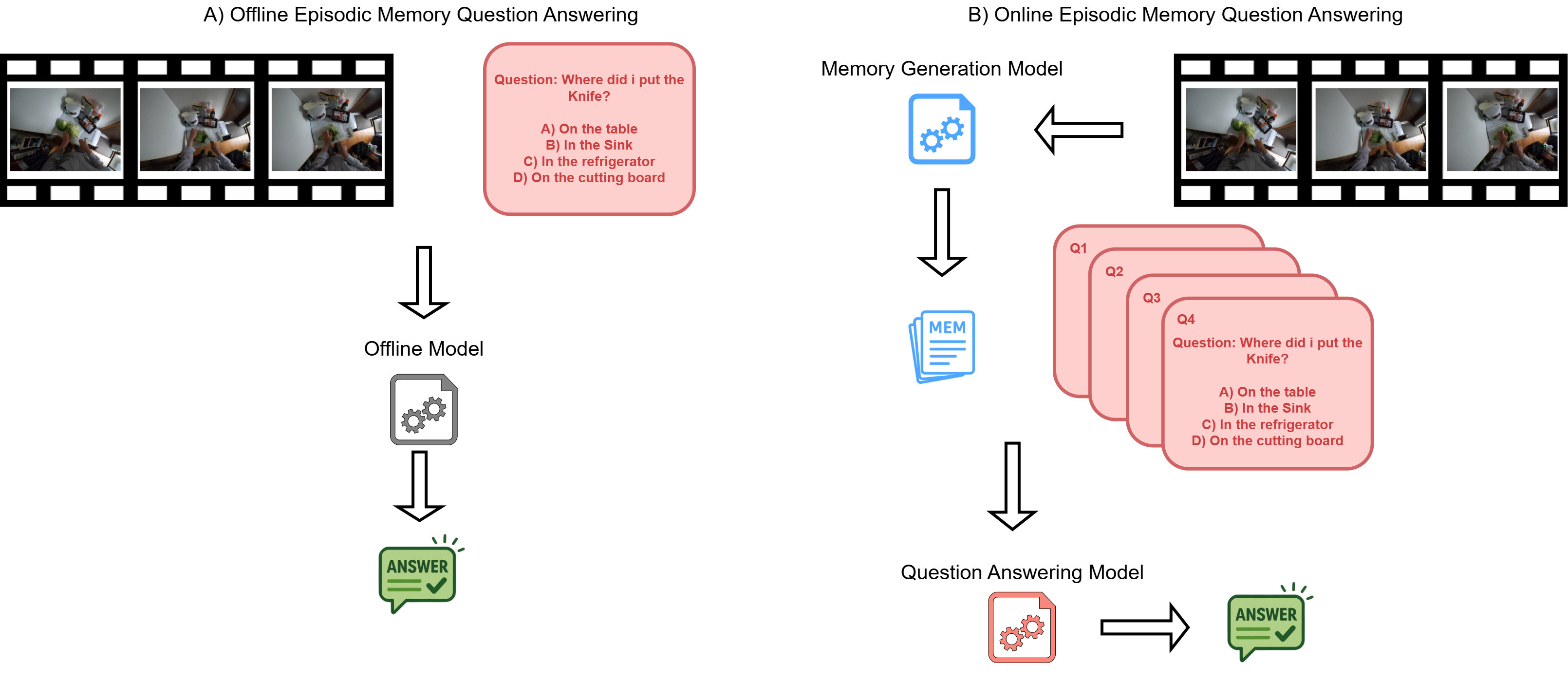
Giuseppe Lando , Rosario Forte , Giovanni Maria Farinella , Antonino Furnari
Proceedings of the 23rd International Conference on Image Analysis and Processing (ICIAP)

Chiara Plizzari , Gabriele Goletto , Antonino Furnari , Siddhant Bansal , Francesco Ragusa , Giovanni Maria Farinella , Dima Damen , Tatiana Tommasi
International Journal of Computer Vision (IJCV)
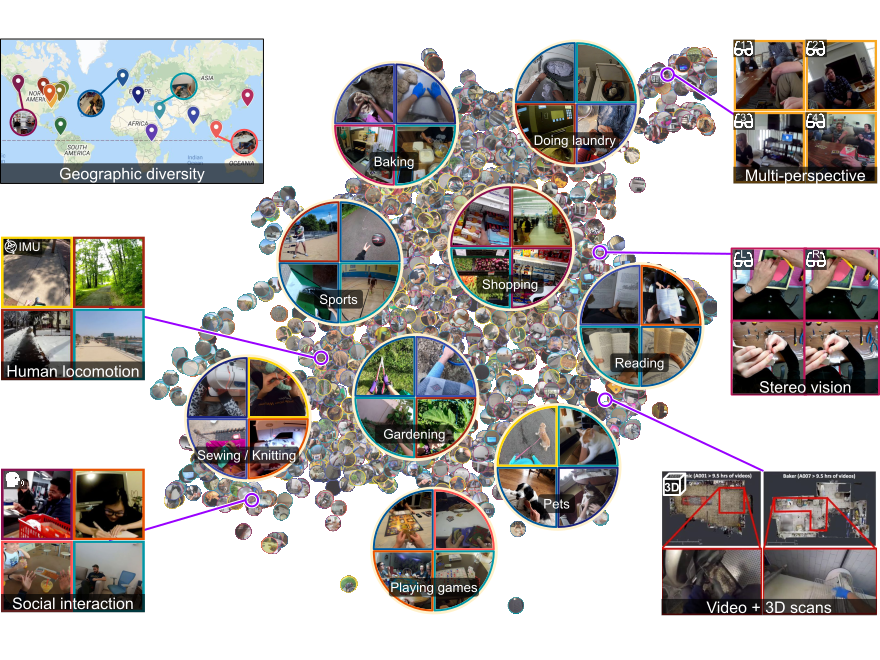
Kristen Grauman , Andrew Westbury , Eugene Byrne , Vincent Cartillier , Zachary Chavis , Antonino Furnari , Rohit Girdhar , Jackson Hamburger , Hao Jiang , Devansh Kukreja , Miao Liu , Xingyu Liu , Miguel Martin , Tushar Nagarajan , Ilija Radosavovic , Santhosh Kumar Ramakrishnan , Fiona Ryan , Jayant Sharma , Michael Wray , Mengmeng Xu , Eric Zhongcong Xu , Chen Zhao , Siddhant Bansal , Dhruv Batra , Sean Crane , Tien Do , Morrie Doulaty , Akshay Erapalli , Christoph Feichtenhofer , Adriano Fragomeni , Qichen Fu , Abrham Gebreselasie , Cristina Gonzalez , James Hillis , Xuhua Huang , Yifei Huang , Wenqi Jia , Weslie Khoo , Jachym Kolar , Satwik Kottur , Anurag Kumar , Federico Landini , Chao Li , Yanghao Li , Zhenqiang Li , Karttikeya Mangalam , Raghava Modhugu , Jonathan Munro , Tullie Murrell , Takumi Nishiyasu , Will Price , Paola Ruiz Puentes , Merey Ramazanova , Leda Sari , Kiran Somasundaram , Audrey Southerland , Yusuke Sugano , Ruijie Tao , Minh Vo , Yuchen Wang , Xindi Wu , Takuma Yagi , Ziwei Zhao , Yunyi Zhu , Pablo Arbelaez , David Crandall , Dima Damen , Giovanni Maria Farinella , Christian Fuegen , Bernard Ghanem , Vamsi Krishna Ithapu , C.V. Jawahar , Hanbyul Joo , Kris Kitani , Haizhou Li , Richard Newcombe , Aude Oliva , Hyun Soo Park , James M. Rehg , Yoichi Sato , Jianbo Shi , Mike Zheng Shou , Antonio Torralba , Lorenzo Torresani , Mingfei Yan , Jitendra Malik
IEEE Transactions on Pattern Analysis and Machine Intelligence
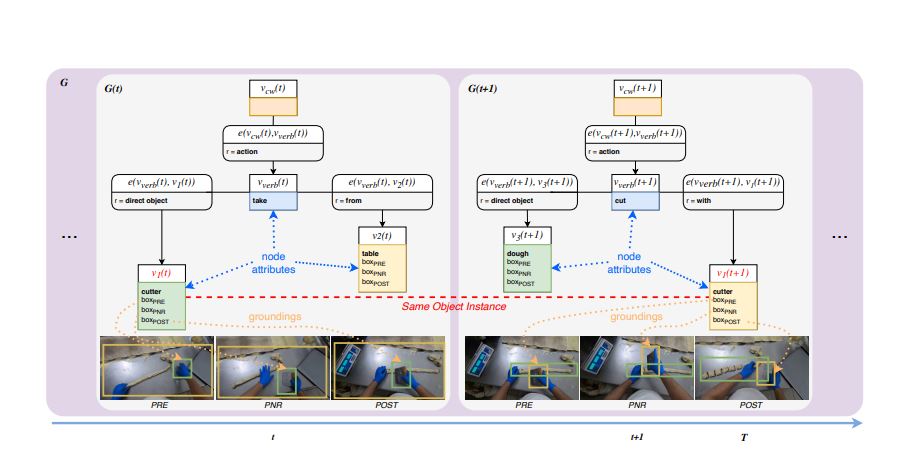
Ivan Rodin , Antonino Furnari , Kyle Min , Subarna Tripathi , Giovanni Maria Farinella
Conference on Computer Vision and Pattern Recognition (CVPR)
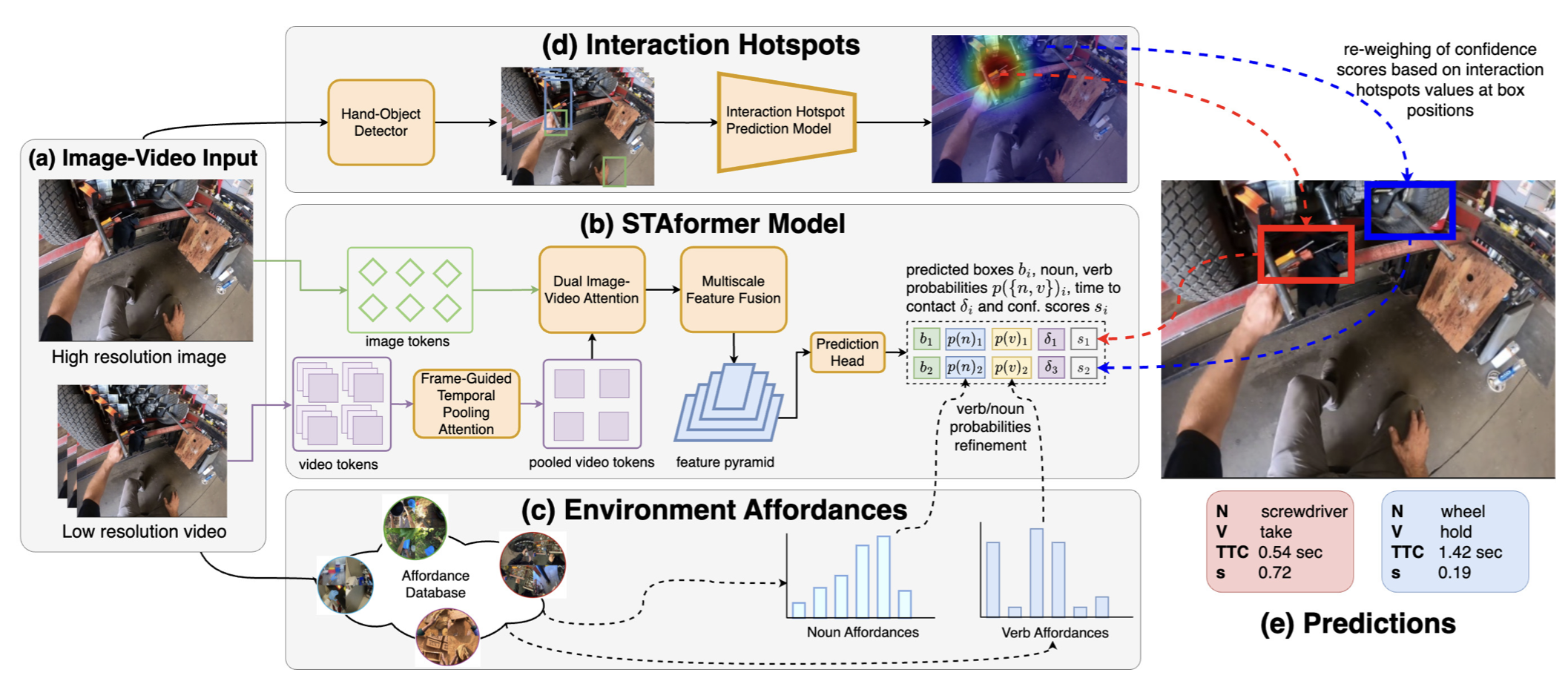
Lorenzo Mur-Labadia , Ruben Martinez-Cantin , Josechu Guerrero , Giovanni Maria Farinella , Antonino Furnari
European Conference on Computer Vision (ECCV)
Luigi Seminara , Giovanni Maria Farinella , Antonino Furnari
Advances in Neural Information Processing Systems
Kristen Grauman , Andrew Westbury , Lorenzo Torresani , Kris Kitani , Jitendra Malik , Triantafyllos Afouras , Kumar Ashutosh , Vijay Baiyya , Siddhant Bansal , Bikram Boote , Eugene Byrne , Zach Chavis , Joya Chen , Feng Cheng , Fu-Jen Chu , Sean Crane , Avijit Dasgupta , Jing Dong , Maria Escobar , Cristhian Forigua , Abrham Gebreselasie , Sanjay Haresh , Jing Huang , Md Mohaiminul Islam , Suyog Jain , Rawal Khirodkar , Devansh Kukreja , Kevin J Liang , Jia-Wei Liu , Sagnik Majumder , Yongsen Mao , Miguel Martin , Effrosyni Mavroudi , Tushar Nagarajan , Francesco Ragusa , Santhosh Kumar Ramakrishnan , Luigi Seminara , Arjun Somayazulu , Yale Song , Shan Su , Zihui Xue , Edward Zhang , Jinxu Zhang , Angela Castillo , Changan Chen , Xinzhu Fu , Ryosuke Furuta , Cristina Gonzalez , Prince Gupta , Jiabo Hu , Yifei Huang , Yiming Huang , Weslie Khoo , Anush Kumar , Robert Kuo , Sach Lakhavani , Miao Liu , Mi Luo , Zhengyi Luo , Brighid Meredith , Austin Miller , Oluwatumininu Oguntola , Xiaqing Pan , Penny Peng , Shraman Pramanick , Merey Ramazanova , Fiona Ryan , Wei Shan , Kiran Somasundaram , Chenan Song , Audrey Southerland , Masatoshi Tateno , Huiyu Wang , Yuchen Wang , Takuma Yagi , Mingfei Yan , Xitong Yang , Zecheng Yu , Shengxin Cindy Zha , Chen Zhao , Ziwei Zhao , Zhifan Zhu , Jeff Zhuo , Pablo Arbelaez , Gedas Bertasius , David Crandall , Dima Damen , Jakob Engel , Giovanni Maria Farinella , Antonino Furnari , Bernard Ghanem , Judy Hoffman , C. V. Jawahar , Richard Newcombe , Hyun Soo Park , James M. Rehg , Yoichi Sato , Manolis Savva , Jianbo Shi , Mike Zheng Shou , Michael Wray
Conference on Computer Vision and Pattern Recognition (CVPR)
Alessandro Flaborea , Guido D'Amely , Leonardo Plini , Luca Scofano , Edoardo De Matteis , Antonino Furnari , Giovanni Maria Farinella , Fabio Galasso
Conference on Computer Vision and Pattern Recognition (CVPR)
Camillo Quattrocchi , Antonino Furnari , Daniele Di Mauro , Mario Valerio Giuffrida , Giovanni Maria Farinella
European Conference on Computer Vision (ECCV)
Kristen Grauman , Andrew Westbury , Eugene Byrne , Zachary Chavis , Antonino Furnari , Rohit Girdhar , Jackson Hamburger , Hao Jiang , Miao Liu , Xingyu Liu , Miguel Martin , Tushar Nagarajan , Ilija Radosavovic , Santhosh Kumar Ramakrishnan , Fiona Ryan , Jayant Sharma , Michael Wray , Mengmeng Xu , Eric Zhongcong Xu , Chen Zhao , Siddhant Bansal , Dhruv Batra , Vincent Cartillier , Sean Crane , Tien Do , Morrie Doulaty , Akshay Erapalli , Christoph Feichtenhofer , Adriano Fragomeni , Qichen Fu , Christian Fuegen , Abrham Gebreselasie , Cristina Gonzalez , James Hillis , Xuhua Huang , Yifei Huang , Wenqi Jia , Weslie Khoo , Jachym Kolar , Satwik Kottur , Anurag Kumar , Federico Landini , Chao Li , Yanghao Li , Zhenqiang Li , Karttikeya Mangalam , Raghava Modhugu , Jonathan Munro , Tullie Murrell , Takumi Nishiyasu , Will Price , Paola Ruiz Puentes , Merey Ramazanova , Leda Sari , Kiran Somasundaram , Audrey Southerland , Yusuke Sugano , Ruijie Tao , Minh Vo , Yuchen Wang , Xindi Wu , Takuma Yagi , Yunyi Zhu , Pablo Arbelaez , David Crandall , Dima Damen , Giovanni Maria Farinella , Bernard Ghanem , Vamsi Krishna Ithapu , C. V. Jawahar , Hanbyul Joo , Kris Kitani , Haizhou Li , Richard Newcombe , Aude Oliva , Hyun Soo Park , James M. Rehg , Yoichi Sato , Jianbo Shi , Mike Zheng Shou , Antonio Torralba , Lorenzo Torresani , Mingfei Yan , Jitendra Malik
IEEE/CVF International Conference on Computer Vision and Pattern Recognition
Talks & Presentations
Towards Always‑On Wearable AI That Perceives, Understands, and Assists
VITA Workshop @ CVPR 2026
SlidesCo-organizing the EgoVis Workshop
CVPR 2026
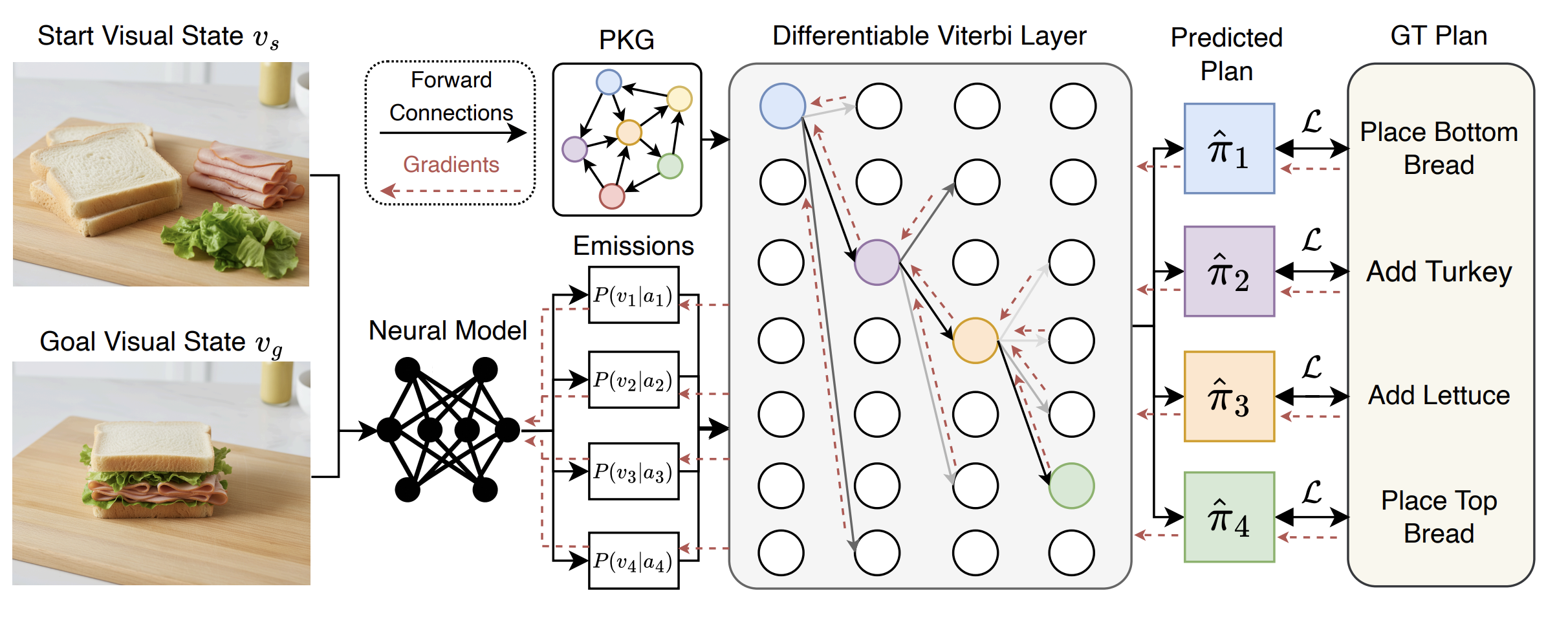
ViterbiPlanNet: Injecting Procedural Knowledge via Differentiable Viterbi for Planning in Instructional Videos
CVPR 2026 Workshops & Main Conference
Extended Abstracts (Collab. with Other Groups)
CVPR 2026 Workshops
Towards Embodied Human-AI Symbiosis with Egocentric Vision
MaP Robotics, Vision, and Controls Talks — ETH Zurich
SlidesTowards an Embodied Understanding of Human Behaviour with Egocentric Vision
University of Pennsylvania - Summer GRASP Seminars
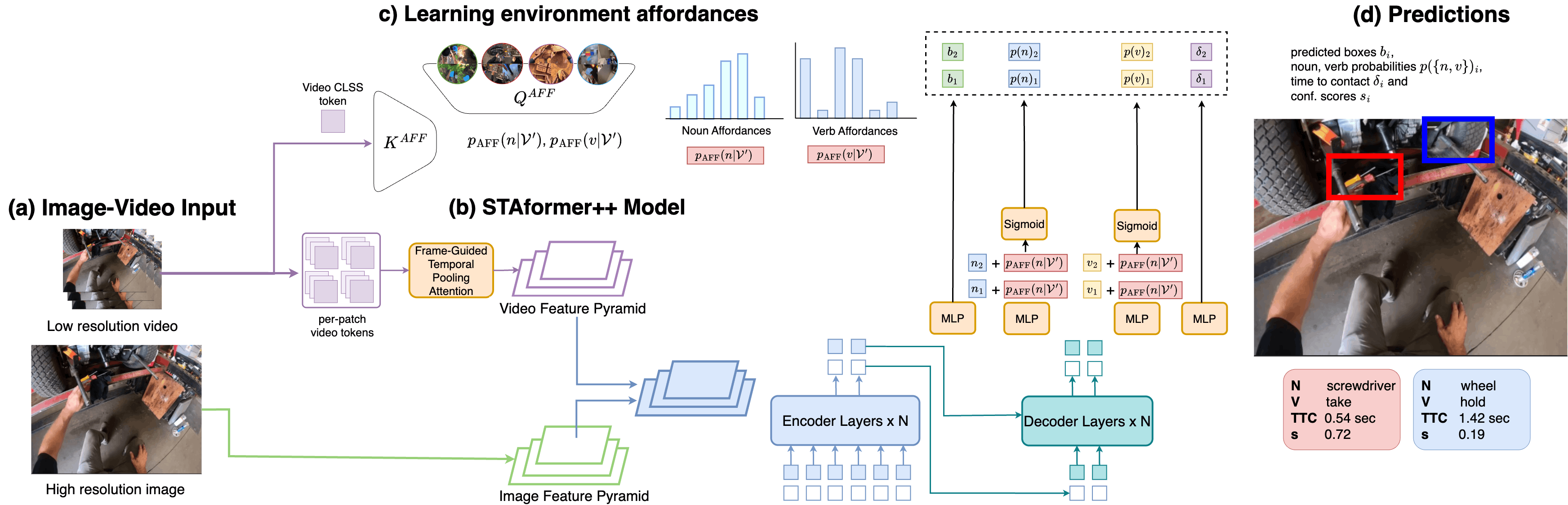
SlidesPrecognition in Egocentric Vision: From Short-Term Interactions to Long-Term Procedural Understanding
Precognition Workshop @ CVPR 2025
SlidesEgocentric Vision: An Anticipatory Sensor for Wearable Robots - From Action Forecasting to Procedural Understanding
Enhancing human mobility: From computer vision-based motion tracking to wearable assistive robot control workshop @ ICRA 2025
SlidesBeyond atomic actions: towards long-form and procedural understanding of egocentric videos
Video Understanding Applications workshop @ BMVC 2024, Glagow, UK
SlidesDemocratizing the Access to AI through Egocentric Vision
Research Seminars, Master in Robotics, Graphics and Computer Vision - University of Zaragoza
EgoExo4D Overview
Aria Tutorial @ ECCV 2024, Milan, IT
From Perception to Partnership: A Path Toward Collaborative AI via Egocentric Vision
Bocconi University
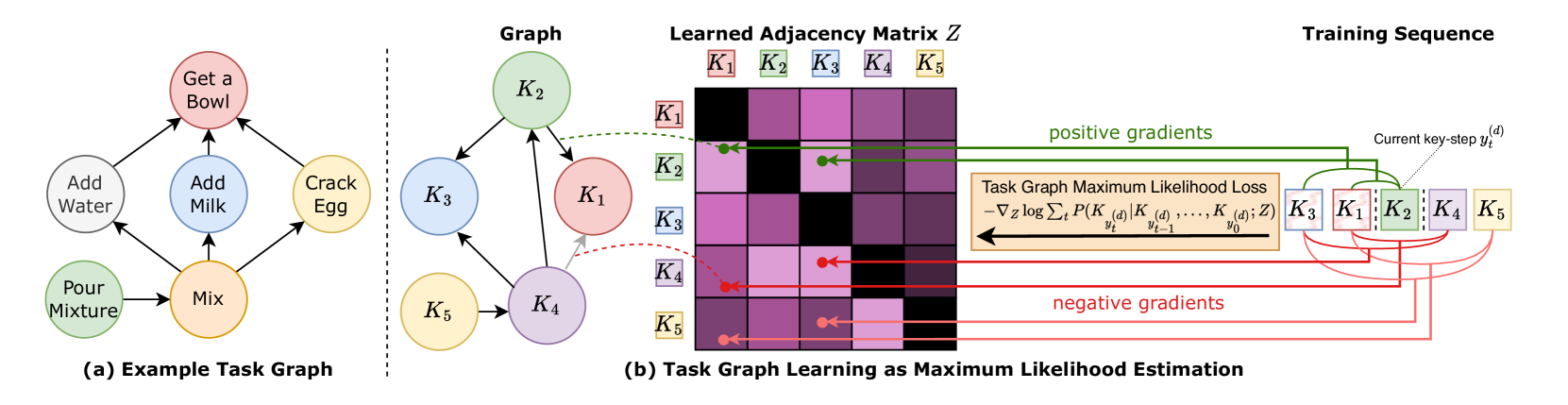
Action-Centric Graphs for Procedural Video Understanding
ICCV 2025 Workshop on Scene Graphs and Graph Representation Learning
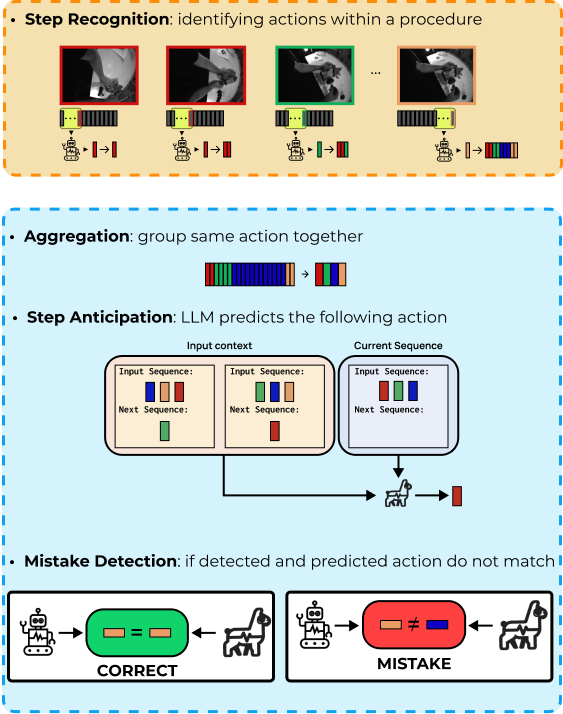
SlidesFrom Observation to Intervention: Mistake Detection and Procedural Assistance in Egocentric Vision
ICCV 2025 Workshop on AI-driven Skilled Activity Understanding, Assessment & Feedback Generation
SlidesEgocentric Vision in the Kitchen: From Interaction Prediction to Recipe‑Level Understanding
AICV4Food workshop @ ICIAP 2025
SlidesLearning to Act like a Pro: Discovering Procedural Models of Expert Workflows for Assistance and Validation
AMBEATion Workshop
SlidesLearning to See the World from an Egocentric Perspective
Universidad Carlos III de Madrid (UC3M)
SlidesEgocentric Vision as a Bridge for Human-AI Collaboration
Eyes Of The Future: Integrating Artificial Intelligence in Smart Eyewear (IAISE) workshop @ IJCNN 2025
SlidesEgocentric Vision for Procedural Video Understanding
Egocentric Perception & Action for Robot Learning workshop at RSS 2025, Los Angeles, US
Slides